Workflow Enhancement - 3.4
- Sagar Kapare
- andreas
- Terence Yim
Goals
- JIRA: CDAP-3969: CDAP should offer a temporary location to store results between jobs of a workflow.
- JIRA: CDAP-4075: Error handling for Workflows.
Checklist
- User stories documented (Sagar)
- User stories reviewed (Nitin)
- Design documented (Sagar)
- Design reviewed (Albert/Terence/Andreas)
- Feature merged (Sagar)
- Examples and guides (Sagar)
- Integration tests (Sagar)
- Documentation for feature (Sagar)
- Blog post
Terminology
In this document I used the term local dataset to refer to the datasets which are defined inside the scope of the Workflow, however temporary, transient refer to same thing. We can finalize which term to use.
Local dataset Definition
Local datasets are the datasets which are configured inside the Workflow. These datasets are created by the Workflow driver for each run and are deleted once the Workflow run finishes. In some situations user can choose not to delete them for the debugging purpose by providing appropriate runtime arguments. These datasets should be hidden from the normal list dataset calls and only visible from the Workflow run level UI page for exploring/debugging purpose.
Use Cases
- JIRA: CDAP-3969: CDAP should offer a temporary location to store results between jobs of a workflow.
Case A)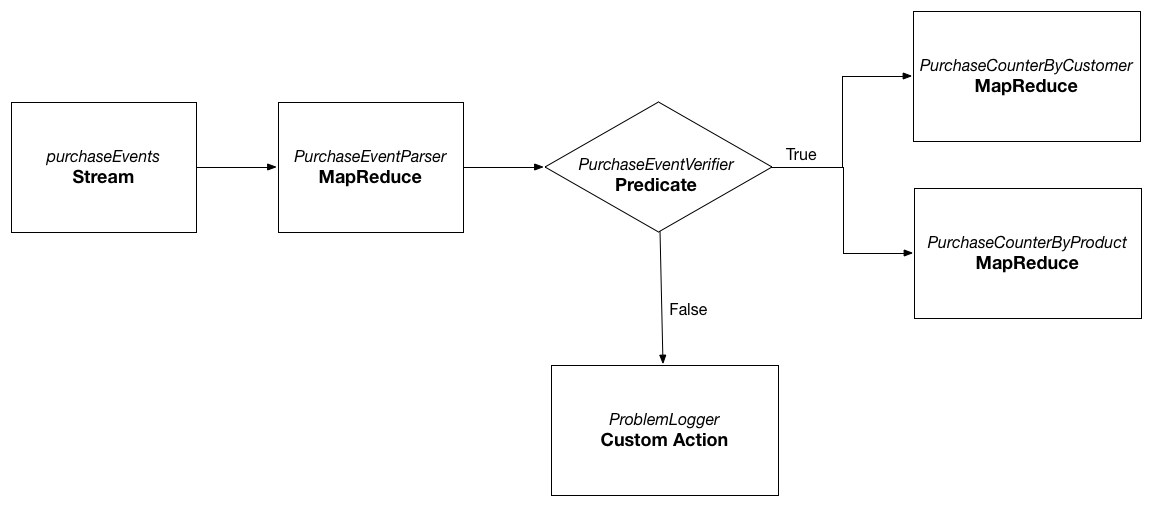
Consider the above sample workflow from CDAP-Workflow guide. The goal is to process the raw purchase events from the purchaseEvents stream and find the purchases made by each customer and purchases made for the particular product. When workflow runs, PurchaseEventParser reads the raw events from the purchaseEvents stream and writes the purchase objects to the purchaseRecords dataset. This dataset is later used by PurchaseCounterByCustomer and PurchaseCounterByProduct MapReduce programs as input to create the datasets customerPurchases and productPurchases respectively. Note that when the workflow completes, user is only interested in the final datasets that are created by the Workflow run: customerPurchases and productPurchases. The dataset purchaseRecords created by the MapReduce program PurchaseEventParser is local to the Workflow and no longer required when the workflow run is completed.
Case B)
MapReduce program in CDAP can output to the multiple datasets. Consider that the above Workflow can be modified, so that PurchaseEventParser can also write to the errorRecords along with the purchaseRecords dataset. The errorRecords contains the raw events from the purchaseEvents stream for which parsing failed. In this case, the errorRecords may not be local since user may want to perform some analysis on it using another CDAP application to find out the sources which are emitting the bad data frequently.
Andreas: I don't understand the significance of case B. All this says is that some output datasets are not local. But we already know that? - [Sagar: This is simply to note down the use case where not all the outputs of the MapReduce program can be local.]Case C)
If for some reason, MapReduce program PurchaseEventParser is not generating the required amount of the data, user may want to keep the dataset purchaseRecords even after the run of the Workflow completes, so that he can debug it further.Case D)
Workflow DAG on the UI shows which nodes will be executed by the Workflow and in what order. User can click on any link between the nodes and mark it as local so that it can be kept after the Workflow run. This will cause the output of the source node for that link to be marked as local. User can again click on the link and mark the output as non-local. Solving this use case has few challenges though: MapReduce program can write to multiple output datasets which is decided dynamically during the Workflow run. How would we know before hand that which dataset to be marked as local. Also user can decide to have only one of the output dataset of MapReduce program as local. How would it work in case the link is between the custom action and MapReduce program or custom action and predicates?
Andreas: I think this is the wrong approach. Due to "dynamic datasets", the UI cannot know what datasets are read/written by an action. Also, an edge in the workflow represents a transition in control flow, not data flow: it does not represent a dataset. The next action in the workflow may actually read a dataset completely unrelated to the previous action. Didn't we agree that local datasets are declared at the scope of the workflow (that is, as part of workflow spec), and all the user can do at runtime is specify whether it should be preserved for triage purposes at the end of the run? I believe we also said that there can be an onError or onFinish action that gets called when the workflow terminates, and in the code of that action the developer can instruct the workflow driver to keep some of the local datasets for triage?[Sagar: onError or onFinish need to be design further as a part of CDAP-4075. One possible way is to have access to the WorkflowToken in these methods, so that user can put values in the token which are indicative of whether the dataset should be deleted or not.] - JIRA: CDAP-4075: Error handling for Workflows.
Case A) When the Workflow fails for some reason, user may want to notify appropriate parties via email, possibly with the cause of the failure and the node at which the Workflow failed.
Case B) When the Workflow fails for some reason at a particular node, user may want to cleanup the datasets and files created by the previous nodes in the Workflow.
Case C) In case of hydrator pipeline, user may want to delete the data from the source when the Workflow run is complete.
User Stories
- As a developer of the Workflow, I want the ability to specify that the particular dataset used in the Workflow is local to it, so that Workflow system can create it at the start of every run and cleans it up after the run completes. (CDAP-3969)
- As a developer of the Workflow, I should be able to specify whether the local datasets created by the Workflow run should be deleted or not after the Workflow run finishes. This way I can do some debugging on the them once the Workflow run is failed. (CDAP-3969)
Terence: If it is retained, how the user gain access and interact with those local datasets? As per the definition, local datasets "should be hidden from the normal list dataset calls and only visible from the Workflow run level UI page for exploring/debugging purpose". [Sagar: When dataset is created in the Workflow driver, it can add a special property say .dataset.workflow.internal to the dataset. While listing the datasets, we can filter out the datasets which have this property, so that the list dataset call does not show them. On the Workflow run level UI page, we can explicitly call the "/data/datasets/localdatasetname" so that it can be explored further given that the dataset itself is explorable. Also local dataset can be accessed from the other applications in the same namespace since the name of the local dataset would simply be datasetName.<workflow_run_id>.] - I want the ability to delete the local datasets generated for the particular Workflow run. (CDAP-3969)
I should be able to specify whether to keep the local dataset even after the Workflow run is finished. (CDAP-3969)
Andreas: This seems identical to 2. [Sagar: Oh yes. Striking it.]- As a developer of the Workflow, I want ability to specify the functionality(such as sending an email) that will get executed when the Workflow finishes successfully. (CDAP-4075)
- As a developer of the Workflow, I want ability to specify the functionality(such as sending an email) that will get executed when the Workflow fails at any point in time. I want access to the cause of the failure and the node at which the workflow failed. (CDAP-4075)
- As a developer of the Workflow, if the workflows fails, I want the ability instruct the workflow system to not delete the local datasets, for triage purposes. [Sagar: This is good point. Will add the design for it.]
Approach for CDAP-3969
Consider again the Workflow mentioned in the use case above.
In above Workflow, the datasets errorRecords, customerPurchases, and productPurchases are non-local datasets. They can be defined inside the application as -
public class WorkflowApplication extends AbstractApplication { ... // define non-local datasets createDataset("errorRecords", KeyValueTable.class); createDataset("customerPurchases", KeyValueTable.class); createDataset("productPurchases", KeyValueTable.class); ... }Since purchaseRecords is the dataset local to the Workflow, it can be defined inside the Workflow configurer method as -
public class PurchaseWorkflow extends AbstractWorkflow { @Override protected void configure() { setName("PurchaseWorkflow"); ... // create the Workflow local datasets here - createLocalDataset("PurchaseRecords", KeyValueTable.class); ... addMapReduce("PurchaseEventParser"); ... } }- When the application is deployed, following datasets are created - errorRecords, customerPurchases, and productPurchases
- If MapReduce program PurchaseEventParser is ran by itself, outside the Workflow, it would fail, since the purchaseRecords is not defined in the namespace scope. Andreas: actually, the namespace scope, we don't have application scope for datasets (they are visible across all apps in the namespace).[Sagar: Updated to the namespace scope.] Its user's responsibility to make sure that the dataset exists in the correct scope.
User can choose to not to delete the local dataset even after the Workflow run is complete by specifying the runtime argument.
// To keep the Workflow local purchaseRecords dataset even after the Workflow run is completed following runtime argument can be specified - dataset.purchaseRecords.keep.local=true // In order to keep all the local datasets even after the Workflow run is completed following runtime argument can be specified - dataset.*.keep.local=true
- Datasets configured as local to the Workflow are stored as a part of the Workflow specification. When Workflow run is started, these datasets can be created. The name of the local dataset would be datasetName.<workflow_run_id>. Andreas: I think what you mean is: they are stored as part of the workflow spec, and when the workflow starts, they are created.[Sagar: Fixed.]
Mapping of the <datasetName, localDatasetName> would be passed to the dataset framework instance so that all calls to the dataset would be routed to the appropriate dataset instance. Possible approach is -
// Class to forward the calls to the delegate class ForwardingDatasetFramework implements DatasetFramework { private final Map<String, String> datasetNameMapping; private final DatasetFramework delegate; public ForwardingDatasetFramework(DatasetFramework datasetFramework, Map<String, String> datasetNameMapping) { this.delegate = datasetFramework; this.datasetNameMapping = datasetNameMapping; } // All required calls would be intercepted here. For e.g. @Override public <T extends Dataset> T getDataset( Id.DatasetInstance datasetInstanceId, Map<String, String> arguments, @Nullable ClassLoader classLoader) throws DatasetManagementException, IOException { if (datasetNameMapping.containsKey(datasetInstanceId.getId())) { datasetInstanceId = Id.DatasetInstance.from(datasetInstanceId.getNamespaceId(), datasetNameMapping.get(datasetInstanceId.getId())); } return getDataset(datasetInstanceId, arguments, classLoader, null); } } // ForwardingDatasetFramework can then be created in WorkflowDriver (in order to use it for custom action and predicates), MapReduceProgramRunner, and SparkProgramRunner from injected DatasetFramework instance.Andreas: You mean
Id.DatasetInstance.from(datasetInstanceId.getNamespaceId(), datasetMapping.get(datasetInstanceId.getId())), right? [Sagar: Yes. Corrected.]Similar change mentioned in the (7) would require in MapperWrapper and ReducerWrapper, since we create the instance of the datasetFramework over there as well.
- Once the Workflow run completes, the corresponding local datasets can be deleted from the WorkflowDriver, depending on the runtime argument dataset.*.keep.local as mentioned in (5).
Lineage for the Local datasets(TBD)
REST API Changes
- Datasets local to the Workflow should not be listed in the list dataset API. This will simply hide the local datasets from the user. However there is still possibility for the user to get access to the local datasets and use them inside the other applications.
Andreas: How? And what do you mean by "inside the applications"? Other applications? How will they do that?
Sagar: When dataset is created in the Workflow driver, it can add a special property say .dataset.workflow.internal to the dataset. While listing the datasets, we can filter out the datasets which have this property, so that the list dataset call does not show them. On the Workflow run level UI page, we can explicitly call the "/data/datasets/localdatasetname" so that it can be explored further given that the dataset itself is explorable. Also local dataset can be accessed from the other applications in the same namespace since the name of the local dataset would simply be datasetName.<workflow_run_id> API to list the local datasets if they are available.
GET <base-url>/namespaces/{namespace}/apps/{app-id}/workflows/{workflow-id}/runs/{run-id}/localdatasetsWe will need a way to delete the local datasets created for a particular Workflow run if user set the dataset.*.keep.local for that run.
DELETE <base-url>/namespaces/{namespace}/apps/{app-id}/workflows/{workflow-id}/runs/{run-id}/localdatasets
UI Changes
- For every Workflow run, we will need to add the new tab for listing the local datasets.
- These datasets if marked explorable, should be explorable from the UI.
- We need ability to delete the local datasets from UI.
Approach for CDAP-4075
Workflow will have onFinish method which will be called at the end of the every Workflow run.
/** * Called when the Workflow run finishes either successfully or on failure. * @param isSucceeded flag to indicate the success/failure * @param context the Workflow context * @param state the state of the Workflow */ void onFinish(boolean isSucceeded, WorkflowContext context, WorkflowState state);
WorkflowState class encapsulate the status of all the nodes executed by the Workflow along with the failure information if any, as -
public final class WorkflowState { private final Map<String, WorkflowNodeState> nodeState; // Failure information for the Workflow run private WorkflowFailureInfo info; } public final class WorkflowNodeState { private final String nodeId; private final ProgramRunStatus nodeStatus; private final RunId runId; } public final class WorkflowFailureInfo { // id of the node for which the failure occurred in the Workflow. private final String failedNodeId; // failure cause private final Throwable failureCause; }- WorkflowState can be stored as property in the RunRecord of the Workflow. This property will be updated when the action in the Workflow starts and ends.
- When the Workflow run finishes, before calling the onFinish method on the Workflow, WorkflowState for that run can be fetched from the store and passed on to the onFinish method. WorkflowState can be used by user in the onFinish method to check what actions ran and accordingly cleanup can be performed.
- User can update the WorkflowToken in onFinish method, such as changing the preference for the local datasets. (What should be the nodeId used for these updates?)
- Similar to the onFinish method of the MapReduce, Workflow.onFinish will also run in short transaction as a first step. Ideally user would have control over what transaction should be started in the onFinish.
Created in 2020 by Google Inc.