Log Framework
- Vinisha Shah
- Shankar Selvam
- Terence Yim
Checklist
- User Stories Documented
- User Stories Reviewed
- Design Reviewed
- APIs reviewed
- Release priorities assigned
- Test cases reviewed
- Blog post
Introduction
Support Pluggable Log Saver Plugins in Log Saver for users to provide custom plugins to configure and store log messages and also improve log saver for other functionalities like versioning, impersonation, resilience, etc.
Existing Problems
Impersonation
Current implementation of LogSaver uses namespace directory to store logs which makes LogSaver dependent on impersonation. Impersonation could be avoided for logsaver if log files storage is not namespaced. For example, use a common root directory outside any CDAP namespace to store log files and use namespace-version-id to differentiate between namespaces. This would prohibit the users to look at their log files directly in HDFS as they are owned by "cdap". We need to consider if we have to provide options to make the "user" flexible for log files written by log saver plugins.
Entity Deletion and Recreation
LogSaver currently does not handle the case where a given entity is deleted and recreated with the same name. This is a common scenario on development clusters where developers can delete and recreate entity with the same name. There are couple of open issues present <link>
Pluggable Log Appenders
User might want to configure LogSaver to collect logs at different level and also write log messages at different destination. Having capability to add custom LogAppender will allow users to implement custom logic for logs in addition to existing CDAP LogSaver. For example, user might want to collect debug logs per application and store them on HDFS at application-dir/{debug.log} location.
DataStructures
TODO: Look into improving messageTable used for sorting log messages.
Resilience
Making LogSaver resilient to failure scenarios.
TODO: Add more details
Goals
- Provides a unified framework for processing log events read off from the transport (Kafka currently).
- Allows arbitrary number of processors to process the log events.
- Provides implementations for common processors (e.g write to HDFS, rotation, expiration... etc).
User Stories
- For each application, user wants to collect the application's logs into multiple logs files based on log level
- For each application, user wants to configure a location in HDFS to be used to store the collected logs.
- For each application, User wants the application log files stored in text format.
- For each application, User would wants to configure the RotationPolicy of log files.
- For each application, user wants to configure different layout for formatting log messages for the different log files generated.
- User wants to group log messages at application level and write multiple separate log files for each application. Example:
application-dir/{audit.log, metrics.log, debug.log} - User wants to write these log files to a configurable path in HDFS.
- User wants to configure log saver extension using logback configuration.
- User also wants to be able to configure rolling policy for these log files similar to log-back.
Design
Principles
- Establish a clear role separation between the framework and individual processor
- Framework responsibilities
- Reading log events from the log transport
- Transport offset management
- Grouping, buffering and sorting of log events
- Configuration of log processors
- Defines contract and services between the framework and log processors
- Lifecycle management (instantiate, process, flush, destroy)
- Impersonation
- Exception handling policies for exceptions raised by log processors
- Processor responsibilities
- Actual processing of events (mostly writing to somewhere)
- Files and metadata management
- Framework responsibilities
- Scalability
- Memory usage should be relatively constant regardless of the log events rate
- It can varies depending on individual event size (message length, stacktrace, etc.), but it shouldn't vary too much
- Memory usage can be proportional to number of log processors
- Memory usage can be proportional to number of program/application logs being processed by the same log process
- Scaling to multiple JVM processes should only be along with the number of concurrent programs/applications running
- Memory usage should be relatively constant regardless of the log events rate
- Transport neutral
- In distributed mode, Kafka is being used. We may switch to TMS in future.
- In SDK / unit-test mode, can be just an in memory queue, or using local TMS.
Log Processing Framework
As mentioned above, the log processing framework (the framework) is responsible for dispatching log events to individual appenders to process, as well as making CDAP services available for appenders.
Since the Logback Library is a very popular library as logging framework, we are going use it as the contract between the log processing framework and individual log processor.
The Log Processing Framework is responsible for the followings:
- Use logback to configure and instantiate
Appenderbased on a logback configuration file provided to the framework.- It's different than the
logback.xmlused by CDAP processes andlogback-container.xmlused by containers. - It will always validate the CDAP Log Appender is there to avoid missing CDAP functionalities.
- A CDAP extended
LoggerContextclass will be implemented and injected toAppender(s).- Provides CDAP extended functionalities, such as dataset, transaction and metrics, to
Appender.
- Provides CDAP extended functionalities, such as dataset, transaction and metrics, to
- It's different than the
- For each of the
Appenderconfigured, the framework will create an in-memory Log Processing Pipeline. - The framework will manage the lifecycle of the set of Log Processing Pipeline.
- Subscripts to TMS to listen for entity change events, such as CRUD of namespaces, applications, etc (not in 4.1 scope).
- Changes will be propagated to process pipeline to react.
Log Processing Pipeline
For each Appender instance, there is a corresponding Log Processing Pipeline responsible for the followings:
- Read and decode log events from Kafka
- On all the partitions of the "log" topic that are assigned to this Log processing framework
- The events will be buffered and sorted in memory with a configurable max size
- It pretty much a
SortedSet(or aLongSortedSetfrom fastutil to avoid extensive object creation) that is ordered by a unique key that is generated by the log event timestamp and kafka offset - A possible way to generate the unique key is by:
(log_event_timestamp << 20) + (kafka_offset & 0x0fffffL)- Basically multiplying the timestamp by 1M and add the lower 20 bits from the kafka offset
- That gives us 1M events per milliseonds and still the timestamp is valid for 557 years since epoch.
- It pretty much a
- Invoke
Appender.doAppendmethod on log events in the sorting buffer - Persists Kafka offset to a log framework store
- Optionally call
Flushable.flush()if theAppenderimplements thejava.io.Flushableinterface before persisting the Kafka offset - If
Appenderdoesn't implementFlushable, persist the offset periodically - Interim failure in writing the state to state store shouldn't fail the call.
- Dataset service / HBase / TX service can have service interruption
- Under normal operation, once those services become available, the latest states will be persisted.
- The worst case scenario is having some duplicated log events in log file, but it's acceptable.
- E.g. the log processing JVM died before successfully persisting the latest state
- Optionally call
Each Log Processing Pipeline is single thread. This provides a simple mechanism on putting back pressure on the rate of reading from Kafka, without the overhead and complications of multi-thread coordination.
Log Processor
Given that the Logback library is a widely used logging library for SLF4J and is also the logging library used by CDAP, we can simply have log processors implemented through Logback Appender API, as well as configured through usual logback.xml configuration. Here are the highlights for such design:
- Any number of log appenders can be configured through a logging framework specific
logback.xmlfile (not the one used by CDAP nor for containers). - All appender configurations supported by
logback.xmlshould be supported (e.g. appender-ref for delegation/wrapping). - Any existing Logback
Appenderimplementations should be usable without any modification, as long as being properly configured in the runtime environment. - Logback
Appenderalready implements aContextAwareinterface such thatAppendergets an instance ofContextAware. In order to provide CDAP services toAppender, we can have a CDAP implementation ofContextAwareand let theAppenderimplementation do the casting when needed. - Can optionally implements the
Flushableinterface. The framework will call theflushmethod before preserving the transport offset to make sure there is no data loss.
CDAP Log Appender
There will be a log appender implementation for CDAP, replacing the current log-saver. The CDAP log appender is responsible for:
- Write log events into Avro files and maintaining metadata to those files.
- The metadata and the files generated are the only contract between the CDAP log appender and the log query handler.
- Policy based rolling of files / metadata
- Removing files that passed TTL, enforcing max total size/number of files.
- See Logback rolling policy for examples.
- Implements the
Flushableinterface to performhsyncfor HDFS files
CDAP Log File Organizations
In order to get rid of the complication of impersonation and namespace removal issues, the way that log files are organized on file system will be different starting from 4.1.
CDAP Log Handler
- The main differences between pre-4.1 and 4.1 in reading is impersonation.
- Use an extra column in the metadata table (written by the log appender) to identify impersonation is not needed.
- For old log files, impersonation will be based on the namespace of the application.
- Error handling
- Any missing files or corrupted metadata shouldn't fail the reading.
- Those files/entries should simply be skipped
- A WARN message can be logged for debugging purpose
- Those files/entries should simply be skipped
- Any missing files or corrupted metadata shouldn't fail the reading.
Other Log Appenders
- RollingHDFSAppender
- Similar to RollingFileAppender provided by Logback library
- Write to files through the Hadoop HDFS API
Logging Structure and Meta data
All The log files will be created under a common base logging directory. There will be sub-directories for namespace, date, app-name, program-name. The individual files under the directory will be sequence numbered.
Format: /<cdap-base-dir>/logs/<namespace>/<yyyy-mm-dd>/<app-name>/<program-name>/<seq-id.avro> Flow Logs /<cdap-base-dir>/logs/default/2017-1-22/HelloWorld/WhoFlow/0.avro /<cdap-base-dir>/logs/default/2017-1-22/HelloWorld/WhoFlow/1.avro System service Logs /<cdap-base-dir>/logs/system/2017-1-22/services/messaging/0.avro /<cdap-base-dir>/logs/default/2017-1-22/services/messaging/1.avro
During Create New File, we will perform list files in the directory to figure out the next sequence number for the file to be created and use that.
Meta data table
Row-key pattern can remain the same for the new framework as the existing one.
Old Format for rowkey : Rowkey_Prefix(200)LoggingContext Example : 200ns1:app1:program1 New Format for rowkey : Rowkey_Prefix(200)LoggingContext:eventTimeStamp(long)creationTimestamp(long) Example : 300:ns1:app1:program1:ts1ts2 Existing Column Format In Log-Saver : Column Key : <TimeStamp> Column value : Path to file Column Format Changes: ColumnKey : constant_column_key ColumnValue : Path to file Example : rowKey column Value 300ns1:app1:program1:14851785080011485178508101 file (constant) hdfs://<hostname>:8020/cdap/logs/system/2017-01-23/services/transaction/1.avro
Properties for adding new appenders and new log pipelines
| Property | Description | default |
|---|---|---|
| log.process.pipeline.config.dir | A local directory on the CDAP Master that is scanned for log processing pipeline | /opt/cdap/master/ext/logging/config |
| log.process.pipeline.lib.dir | Semicolon-separated list of local directories on the CDAP Master scanned | /opt/cdap/master/ext/logging/lib |
Adding an new custom appender
CDAP Log Framework allows users to implement custom logback appenders. CDAP comes packaged with CDAP Log appender which is used by CDAP system for processing logs from CDAP system and user namespace. It also has RollingLocationLogAppender which is extension of logback's RollingFileAppender to use HDFS.
More information implementing a custom appender can be found here <link>.
Once you have the appender packaged, in order to make it available, you would copy the appender jar to the path denoted by "log.process.pipeline.lib.dir" in your cluster. When the log.saver system container starts up, jar's under this directory will be made available to it.
Creating New Log Pipelines
In CDAP Log Framework, For every logback.xml files configured at the "log.process.pipeline.config.dir" we create a logging pipeline for the file.
A Log Pipeline provides isolation from other log pipelines.
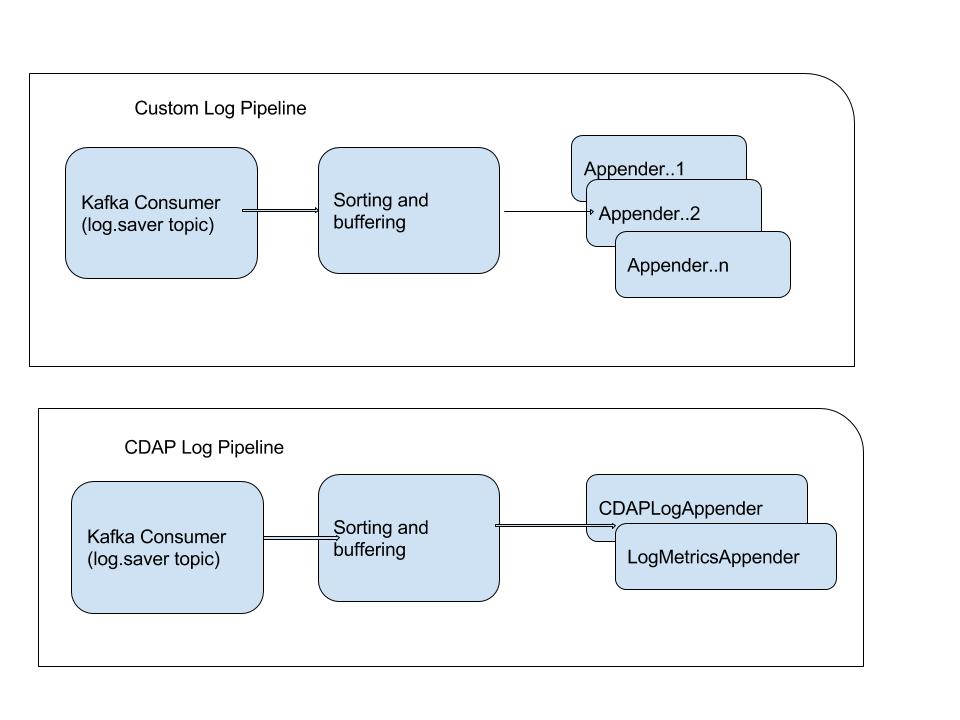
As indicated in the diagram above, each pipeline has to have a unique name. they have separate kafka consumers, this allows the pipelines to have different offsets and a slow processing pipeline won't affect the performance of other logging pipelines.
Each pipeline has to have a unique name, as we use this name for persisting and retrieving metadata (kafka offsets).
Example Logging pipeline configuration used by CDAP system logging - <https://github.com/caskdata/cdap/blob/release/4.1/cdap-watchdog/src/main/resources/cdap-log-pipeline.xml>
Example Custom Logging pipeline configuration using RollingLocationLogAppender - https://github.com/caskdata/cdap/blob/release/4.1/cdap-watchdog/src/test/resources/rolling-appender-logback-test.xml TODO : find a better example for this.
If you would like to create a custom logging pipeline, you would create and configure a logback.xml file, configuring loggers and appenders based on your requirement and place this logback file at the path identified by "log.process.pipeline.config.dir".
Pipeline Properties
CDAP Pipeline has certain common properties for the pipelines that can be configured in cdap-site.xml. They are
Properties |
|---|
log.process.pipeline.buffer.size |
log.process.pipeline.checkpoint.interval.ms |
log.process.pipeline.event.delay.ms |
log.process.pipeline.kafka.fetch.size |
log.process.pipeline.logger.cache.size |
log.process.pipeline.logger.cache.expiration.ms |
log.process.pipeline.auto.buffer.ratio |
Default Values for these can be found in cdap-default.xml.
These properties can also be changed at pipeline level, by overriding these properties by providing a value in the pipeline's logback.xml file for these properties.
Implementing a custom Appender
Users can use any existing logback's appender and also `RollingLocationLogAppender` - Extension of RollingFileLogAppender to use HDFS location in their logging pipelines. In addition, it is also possible for a user to implement their custom appender and make use of it in the log framework.
LogFramework uses the logback's Appender API, So a user wishing to write a custom appender, has to implement Logback's Appender interface in their application.
In Addition access to CDAP's system components like, Datasets, Metrics, LocationFactory, etc. are made available to Appender Context.
Adding Dependency on cdap-watch-dog API will allow you to access AppenderContext in your application. AppenderContext is an extension of logback's LoggerContext.
API changes
New Programmatic APIs
New Java APIs introduced (both user facing and internal)
Deprecated Programmatic APIs
New REST APIs
| Path | Method | Description | Response Code | Response |
|---|---|---|---|---|
| /v3/apps/<app-id> | GET | Returns the application spec for a given application | 200 - On success 404 - When application is not available 500 - Any internal errors |
|
Deprecated REST API
| Path | Method | Description |
|---|---|---|
| /v3/apps/<app-id> | GET | Returns the application spec for a given application |
Namespace Deletion at log saver
- close currently open log files for apps,programs,etc in that namespace - should be done for both CDAP log appender and log processors
- CDAP log appender should either delete or make the files from old namespace unavailable through meta data changes. storage structure has to change from existing format to support this.
- what should be done about the files written by log processors ?
- unprocessed kafka events for the deleted namespace should be dropped.when to stop dropping the events ? if namespace is recreated, how to ensure the new logs from this new namespace are not dropped?
- one option is to have a flag in log saver, when namespace, app,etc is deleted, this flag can be set to drop events in those context
- when these app, namespace are recreated, the flag can be reset to avoid skipping events
Creation:
Namespace creation will notify log framework of all the log saver instances about creation of the namespace; through Rest-api/tms/kafka? Log framework will create uuid for that namespace and store an entry in metadata table for that namespace. The UUID will only be understandable by log saver. Log framework will add uuid information into MDC of LogEvent so that appenders can distinguish between 2 different namespace instances (eventhough their names are same).
Deletion:
Deletion will mark metadata as deleted by log framework and it will be responsible for cleaning up marked_tobe_deleted files. It can do it while doing log clean up. Current implementation takes all namespaces and then scans table considering it namespace and prefix key. If log framework do not have access to all the namespaces (in case of custom/impersonated namespaces) other solution is to go over all the files on hdfs and map them to metadata table and delete files which are older than retention duration. What happens when log files are deleted manually in that case? We should have a REST-Api to repair/make log saver consistent by exposing rest end point to check these inconsitencies and repair them.
Appenders:
When an event is received by appender, appender can check (in metadata) whether the event received is for existing namespace or deleted namespace and can either skip it or process it.
Backwards compatibility:
Can we add upgrade step and do atomic rename for all the log files on hdfs? That way we do not need to support old log file structure
Exception Handling
exception while initializing appender (issues in jar, classpath, could not initialize)
- framework can log error about appender and continue.
- when appender issue is fixed, restart master for it to be picked up.
initialized successfully, exception while processing records
- log appender could throw an unchecked exception while appending
- log fraework, could log this error and continue sending events to the appender
- allow configuring threshold of errors for appenders, after which appender can be disabled by log framework
exception while writing log events to destination (flush)
- when we flush, if there is an exception, appender could retry, however if there is external service issue, causing flush to fail, since appender has not persisted the state, there would be no data loss and can be retried later.
exception while saving meta data to table
- if framework is going to save the meta data, we can have retry logic to persist the states.
On Log Framework Restart
Scenario : When one log appender has issues writing to destination, while other appenders are working fine, the log appender with issue will be behind in processing (lower kafka offset) compared to other log appenders. When the log framework is restarted, how do we handle processing of log messages.
Option 1 : Separate Kafka Consumers for each log appender
Pros:
- This allows log appender to progress separately, the appender with newer offset doesn't have to wait for the appender with older offset to catch up processing.
- reduced memory footprint when one appender is slower compared to other appenders.
Cons:
- sorting and bucketing have to be done for each of the kafka consumer corresponding to the appender.
Note : This would also need each appender to store meta data about the kafka offset for their partitions.
Offset and meta data management for Log Processors
- Offset is at partition level, if we have separate kafka consumers per appender, framework need to store offset information for each appender in meta table.
- Need to uniquely identify namespace.
Storage
CLI Impact or Changes
- Impact #1
- Impact #2
- Impact #3
UI Impact or Changes
- Impact #1
- Impact #2
- Impact #3
Security Impact
What's the impact on Authorization and how does the design take care of this aspect
Impact on Infrastructure Outages
System behavior (if applicable - document impact on downstream [ YARN, HBase etc ] component failures) and how does the design take care of these aspect
Test Scenarios
| Test ID | Test Description | Expected Results |
|---|---|---|
Releases
Release X.Y.Z
Release X.Y.Z
Related Work
- Work #1
- Work #2
- Work #3
Future work
Created in 2020 by Google Inc.