Google NLP Directives
- Andrew Onischuk
- Bhooshan Mogal
General Overview of Google NLP
Google Natural Language API comprises five different services:
- Syntax Analysis
- Sentiment Analysis
- Entity Analysis
- Entity Sentiment Analysis
- Text Classification
Syntax Analysis
For a given text, Google’s syntax analysis will return a breakdown of all words with a rich set of linguistic information for each token. The information can be divided into two parts:
Part of speech. This part contains information about the morphology of each token. For each word, a fine-grained analysis is returned containing its type (noun, verb, etc.), gender, grammatical case, tense, grammatical mood, grammatical voice, and much more.
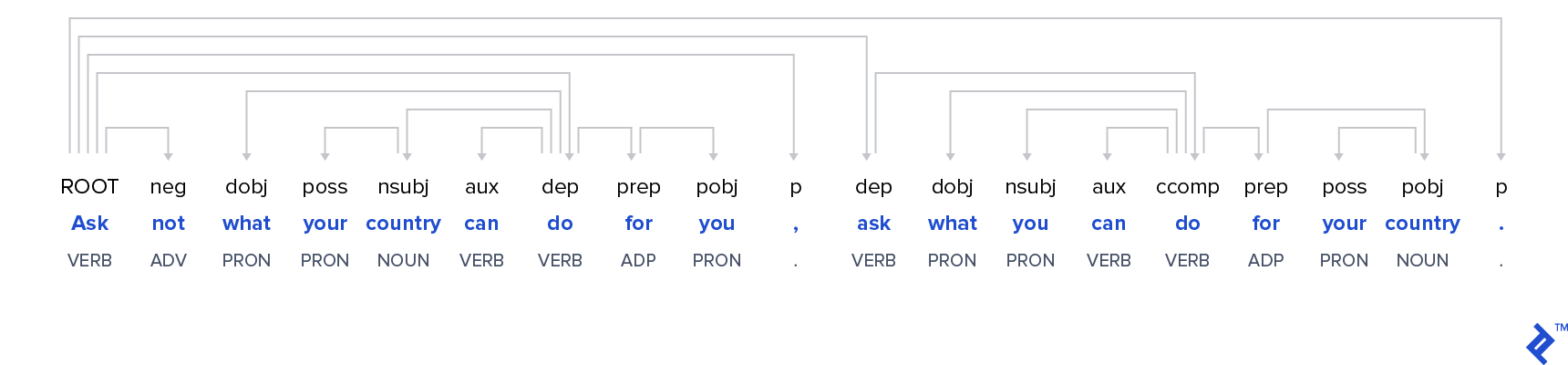
Example sentence: “A computer once beat me at chess, but it was no match for me at kickboxing.”A tag: DET 'computer' tag: NOUN number: SINGULAR 'once' tag: ADV 'beat' tag: VERB mood: INDICATIVE tense: PAST 'me' tag: PRON case: ACCUSATIVE number: SINGULAR person: FIRST at tag: ADP 'chess' tag: NOUN number: SINGULAR ',' tag: PUNCT 'but' tag: CONJ 'it' tag: PRON case: NOMINATIVE gender: NEUTER number: SINGULAR person: THIRD 'was' tag: VERB mood: INDICATIVE number: SINGULAR person: THIRD tense: PAST 'no' tag: DET 'match' tag: NOUN number: SINGULAR 'for' tag: ADP 'kick' tag: NOUN number: SINGULAR 'boxing' tag: NOUN number: SINGULAR '.' tag: PUNCT - Dependency trees. The second part of the return is called a dependency tree, which describes the syntactic structure of each sentence.
Sentiment Analysis
Google’s sentiment analysis will provide the prevailing emotional opinion within a provided text. The API returns two values: The “score” describes the emotional leaning of the text from -1 (negative) to +1 (positive), with 0 being neutral.
The “magnitude” measures the strength of the emotion.
| Input Sentence | Sentiment Results | Interpretation |
|---|---|---|
| The train to London leaves at four o'clock | Score: 0.0 Magnitude: 0.0 | A completely neutral statement, which doesn't contain any emotion at all. |
| This blog post is good. | Score: 0.7 Magnitude: 0.7 | A positive sentiment, but not expressed very strongly. |
| This blog post is good. It was very helpful. The author is amazing. | Score: 0.7 Magnitude: 2.3 | The same sentiment, but expressed much stronger. |
| This blog post is very good. This author is a horrible writer usually, but here he got lucky. | Score: 0.0 Magnitude: 1.6 | The magnitude shows us that there are emotions expressed in this text, but the sentiment shows that they are mixed and not clearly positive or negative. |
Entity Analysis
Entity Analysis is the process of detecting known entities like public figures or landmarks from a given text. Entity detection is very helpful for all kinds of classification and topic modeling tasks.
A salience score is calculated. This score for an entity provides information about the importance or centrality of that entity to the entire document text.
Example: “Robert DeNiro spoke to Martin Scorsese in Hollywood on Christmas Eve in December 2011.”.
| Detected Entity | Additional Information |
|---|---|
| Robert De Niro | type : PERSON salience : 0.5869118 wikipedia_url : https://en.wikipedia.org/wiki/Robert_De_Niro |
| Hollywood | type : LOCATION salience : 0.17918482 wikipedia_url : https://en.wikipedia.org/wiki/Hollywood |
| Martin Scorsese | type : LOCATION salience : 0.17712952 wikipedia_url : https://en.wikipedia.org/wiki/Martin_Scorsese |
| Christmas Eve | type : PERSON salience : 0.056773853 wikipedia_url : https://en.wikipedia.org/wiki/Christmas |
| December 2011 | type : DATE Year: 2011 Month: 12 salience : 0.0 wikipedia_url : - |
| 2011 | type : NUMBER salience : 0.0 wikipedia_url : - |
Entity Sentiment Analysis
If there are models for entity detection and sentiment analysis, it’s only natural to go a step further and combine them to detect the prevailing emotions towards the different entities in a text.
Example: “The author is a horrible writer. The reader is very intelligent on the other hand.”
| Entity | Sentiment |
|---|---|
| author | Salience: 0.8773350715637207 Sentiment: magnitude: 1.899999976158142 score: -0.8999999761581421 |
| reader | Salience: 0.08653714507818222 Sentiment: magnitude: 0.8999999761581421 score: 0.8999999761581421 |
Text Classification
Classifies the input documents into a large set of categories. The categories are structured hierarchical, e.g. the Category “Hobbies & Leisure” has several sub-categories, one of which would be “Hobbies & Leisure/Outdoors” which itself has sub-categories like “Hobbies & Leisure/Outdoors/Fishing.”
Example: “The D3500’s large 24.2 MP DX-format sensor captures richly detailed photos and Full HD movies—even when you shoot in low light. Combined with the rendering power of your NIKKON lens, you can start creating artistic portraits with smooth background blur. With ease.”
| Category | Confidence |
|---|---|
| Arts & Entertainment/Visual Art & Design/Photographic & Digital Arts | 0.95 |
| Hobbies & Leisure | 0.94 |
| Computers & Electronics/Consumer Electronics/Camera & Photo Equipment | 0.85 |
Anotate text
A convenience method that provides all the features that analyzeSentiment, analyzeEntities, and analyzeSyntax provide in one call.
https://cloud.google.com/natural-language/docs/reference/rest/v1/documents/annotateText
Directives Syntax
Directives are named the same way the commands in gcloud cli are named: https://cloud.google.com/sdk/gcloud/reference/ml/language/ but this nlp prefix (please let me know if prefix is needed):
nlp-analyze-syntax <source-column> <destination-column> [authentication-file] [<encoding>] [<language>] nlp-analyze-sentiment <source-column> <destination-column> [authentication-file] [<encoding>] [<language>] nlp-analyze-entities <source-column> <destination-column> [authentication-file] [<encoding>] [<language>] nlp-analyze-entity-sentiment <source-column> <destination-column> [authentication-file] [<encoding>] [<language>] nlp-classify-text <source-column> <destination-column> [authentication-file] [<encoding>] [<language>] nlp-anotate-text <source-column> <destination-column> [authentication-file] [<encoding>] [<language>]
source column*: specifies a column name of an input row which contains the input text.
destination-column*: specifies a column name (type string) of an output row which will contain the results of the execution.
authentication-file: a local path to a file service account key. The details are in "authentication file" section.
encoding: can be set as a part of API call. If it is not set Google NLP Server will assume UTF-8 encoding.
language: can be set as a part of API call (example 'en', 'jp', etc.). If not set, the NLP Server will try to automatically detect a language.
Authentication file
Example of authentication-file (aka. service account key json):
{
"type": "service_account",
"project_id": "myproject-abcd",
"private_key_id": "erse87g9erge8r078g9rese7rg8",
"private_key": "-----BEGIN PRIVATE KEY-----\nQRFGSAFSAF...\n-----END PRIVATE KEY-----\n",
"client_email": "something@project.iam.gserviceaccount.com",
"client_id": "34235412341234534535",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/something"
}
User can download this file from Google Developers console.
For the most google related directive the local path to file is used. Here are we doing the same for consistency. This means that user will have to provide file on each node.
When file parameter is not provided it will take the path from env variables, which is how it will work for GCP case - the most common one.
Return value of directives
Directives will return a json string. This is because the return data can be very complex and it would be pretty troublesome for user to express it in terms of field consisting of multiple layers of nested CDAP schema maps/arrays and even records! Which would be specific and different for every nlp command.
So JSON is a solution. With returned json user can than nicely work using https://github.com/data-integrations/wrangler/blob/develop/wrangler-docs/directives/json-path.md to get the info he needs or maybe write out full json into a sink of his choice.
We can return JSON in API format (the same what gloud cli tool returns). Examples of json for different commands:
https://cloud.google.com/natural-language/docs/analyzing-syntax#language-syntax-string-gcloud
https://cloud.google.com/natural-language/docs/analyzing-sentiment#language-sentiment-string-gcloud
https://cloud.google.com/natural-language/docs/analyzing-entities#language-entities-string-gcloud
Implementation
- There is a Google NLP Java API available. Example of usage: https://cloud.google.com/natural-language/docs/analyzing-syntax#language-syntax-string-java
- The responses there are in protobuf format, which luckily can be transformed to json.
- The code will be located in its own repository called nlp-plugins as opposed to being a part of https://github.com/data-integrations/wrangler/tree/develop/wrangler-core/src/main/java/io/cdap/directives/nlp
- Regarding integration tests. I am thinking of testing it against live NLP instance, instead of mocking it. Since the results of NLP responses can change we should just check for very general things, not checking details.
Examples
Example 1. Syntax analysis
nlp-analyze-syntax body result service_account_key.json
Body is "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show. Sundar Pichai said in his keynote that users love their new Android phones."
Result is a string column, populated with:
{
"sentences": [
{
"text": {
"content": "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.",
"beginOffset": 0
}
},
{
"text": {
"content": "Sundar Pichai said in his keynote that users love their new Android phones.",
"beginOffset": 105
}
}
],
"tokens": [
{
"text": {
"content": "Google",
"beginOffset": 0
},
"partOfSpeech": {
"tag": "NOUN",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "NSUBJ"
},
"lemma": "Google"
},
...
{
"text": {
"content": ".",
"beginOffset": 179
},
"partOfSpeech": {
"tag": "PUNCT",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 20,
"label": "P"
},
"lemma": "."
}
],
"language": "en"
}
Example 2. Sentiment analysis
nlp-analyze-sentiment body result service_account_key.json
Body is "Enjoy your vacation!"
Result is a string column, populated with:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.8
},
"language": "en",
"sentences": [
{
"text": {
"content": "Enjoy your vacation!",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.8,
"score": 0.8
}
}
]
}
Example 3. Entity analysis
nlp-analyze-entities body result service_account_key.json
Body is "President Trump will speak from the White House, located at 1600 Pennsylvania Ave NW, Washington, DC, on October 7."
Result is a string column, populated with:
{
"entities": [
{
"name": "Trump",
"type": "PERSON",
"metadata": {
"mid": "/m/0cqt90",
"wikipedia_url": "https://en.wikipedia.org/wiki/Donald_Trump"
},
"salience": 0.7936003,
"mentions": [
{
"text": {
"content": "Trump",
"beginOffset": 10
},
"type": "PROPER"
},
{
"text": {
"content": "President",
"beginOffset": 0
},
"type": "COMMON"
}
]
},
{
"name": "White House",
"type": "LOCATION",
"metadata": {
"mid": "/m/081sq",
"wikipedia_url": "https://en.wikipedia.org/wiki/White_House"
},
"salience": 0.09172433,
"mentions": [
{
"text": {
"content": "White House",
"beginOffset": 36
},
"type": "PROPER"
}
]
},
{
"name": "Pennsylvania Ave NW",
"type": "LOCATION",
"metadata": {
"mid": "/g/1tgb87cq"
},
"salience": 0.085507184,
"mentions": [
{
"text": {
"content": "Pennsylvania Ave NW",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
{
"name": "Washington, DC",
"type": "LOCATION",
"metadata": {
"mid": "/m/0rh6k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Washington,_D.C."
},
"salience": 0.029168168,
"mentions": [
{
"text": {
"content": "Washington, DC",
"beginOffset": 86
},
"type": "PROPER"
}
]
}
{
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": {
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
}
}
...
],
"language": "en"
}
Example 4. Entity analysis
nlp-analyze-entity-sentiment body result service_account_key.json
Body is "I love R&B music. Marvin Gaye is the best. 'What's Going On' is one of my favorite songs. It was so sad when Marvin Gaye died."
Result is a string column, populated with:
{
"entities":[
{
"mentions":[
{
"sentiment":{
"magnitude":0.9,
"score":0.9
},
"text":{
"beginOffset":7,
"content":"R&B music"
},
"type":"COMMON"
}
],
"metadata":{
},
"name":"R&B music",
"salience":0.5597628,
"sentiment":{
"magnitude":0.9,
"score":0.9
},
"type":"WORK_OF_ART"
},
{
"mentions":[
{
"sentiment":{
"magnitude":0.8,
"score":0.8
},
"text":{
"beginOffset":18,
"content":"Marvin Gaye"
},
"type":"PROPER"
},
{
"sentiment":{
"magnitude":0.1,
"score":-0.1
},
"text":{
"beginOffset":109,
"content":"Marvin Gaye"
},
"type":"PROPER"
}
],
"metadata":{
"mid":"/m/012z8_",
"wikipedia_url":"https://en.wikipedia.org/wiki/Marvin_Gaye"
},
"name":"Marvin Gaye",
"salience":0.18719898,
"sentiment":{
"magnitude":1.0,
"score":0.3
},
"type":"PERSON"
}
...
],
"language":"en"
}
Example 5. Classify content:
nlp-classify-text body result service_account_key.json
Body is "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show. Sundar Pichai said in his keynote that users love their new Android phones."
Result is a string column, populated with:
{
"categories":[
{
"confidence":0.61,
"name":"/Computers & Electronics"
},
{
"confidence":0.53,
"name":"/Internet & Telecom/Mobile & Wireless"
},
{
"confidence":0.53,
"name":"/News"
}
]
}
Example 6. Anotate text:
nlp-anotate-text body result service_account_key.json
Result is a string column, populated with a json which will contain all the data combined from all above jsons
Example of user scenarios (getting information from JSON)
We can put these scenarios into 3 categories.
1) The result of scenario is a single value.
A lot of this can be done via json-path. Fyi Json-path supports conditional gets and nested queries (multiple json-path in each other). Which makes in pretty flexible
2) The result of scenario is a list.
Json-path can return lists. So a lot of these can be implemented as well
3) The result of scenario is a map.
I don't think this is viable to do via wrangler. It would probably require loops. User will have to pass it to something like python transform and write his custom handling code. To do what ever he wants.
Example 1. Take all the nouns from the sentence.
Example sentence: "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show. Sundar Pichai said in his keynote that users love their new Android phones."
Wrangler directives:
nlp-analyze-syntax body result service_account_key.json json-path result nounsList "$.tokens[?(@.partOfSpeech.tag='NOUN')]"
Json:
{
"sentences": [
{
"text": {
"content": "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.",
"beginOffset": 0
}
},
{
"text": {
"content": "Sundar Pichai said in his keynote that users love their new Android phones.",
"beginOffset": 105
}
}
],
"tokens": [
{
"text": {
"content": "Google",
"beginOffset": 0
},
"partOfSpeech": {
"tag": "NOUN",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "NSUBJ"
},
"lemma": "Google"
},
...
{
"text": {
"content": ".",
"beginOffset": 179
},
"partOfSpeech": {
"tag": "PUNCT",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 20,
"label": "P"
},
"lemma": "."
}
],
"language": "en"
}
Result is ['Google', 'Mountain View', 'Android', ...]
Example 2. Get the most important entity (has maximum salience)
Example sentence: "President Trump will speak from the White House, located at 1600 Pennsylvania Ave NW, Washington, DC, on October 7."
nlp-analyze-entity-sentiment body result service_account_key.json json-path result positive_entities "$.entities[?(@.salience = $['.entities.salience.max()'])].name"
Json:
{
"entities": [
{
"name": "Trump",
"type": "PERSON",
"metadata": {
"mid": "/m/0cqt90",
"wikipedia_url": "https://en.wikipedia.org/wiki/Donald_Trump"
},
"salience": 0.7936003,
"mentions": [
{
"text": {
"content": "Trump",
"beginOffset": 10
},
"type": "PROPER"
},
{
"text": {
"content": "President",
"beginOffset": 0
},
"type": "COMMON"
}
]
},
{
"name": "White House",
"type": "LOCATION",
"metadata": {
"mid": "/m/081sq",
"wikipedia_url": "https://en.wikipedia.org/wiki/White_House"
},
"salience": 0.09172433,
"mentions": [
{
"text": {
"content": "White House",
"beginOffset": 36
},
"type": "PROPER"
}
]
},
{
"name": "Pennsylvania Ave NW",
"type": "LOCATION",
"metadata": {
"mid": "/g/1tgb87cq"
},
"salience": 0.085507184,
"mentions": [
{
"text": {
"content": "Pennsylvania Ave NW",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
{
"name": "Washington, DC",
"type": "LOCATION",
"metadata": {
"mid": "/m/0rh6k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Washington,_D.C."
},
"salience": 0.029168168,
"mentions": [
{
"text": {
"content": "Washington, DC",
"beginOffset": 86
},
"type": "PROPER"
}
]
}
{
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": {
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
}
}
...
],
"language": "en"
}
Will return 'Trump'.
Flattened version of JSON for transform
We need to reduce the number of nested things in JSONs in order to transform them into the cdap records correctly. Here is how it's done:
1. Syntax analysis
{
"sentences": [
{
"text": {
"content": "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.",
"beginOffset": 0
}
},
{
"text": {
"content": "Sundar Pichai said in his keynote that users love their new Android phones.",
"beginOffset": 105
}
}
],
"tokens": [
{
"text": {
"content": "Google",
"beginOffset": 0
},
"partOfSpeech": {
"tag": "NOUN",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "NSUBJ"
},
"lemma": "Google"
}
],
"language": "en"
}
Flattened:
{
"sentences": [
{ # record.
"content": "Google, headquartered in Mountain View, unveiled the new Android phone at the Consumer Electronic Show.",
"beginOffset": 0
},
{
"content": "Sundar Pichai said in his keynote that users love their new Android phones.",
"beginOffset": 105
}
],
"tokens": [
{ # record.
"content": "Google",
"beginOffset": 0
"tag": "NOUN",
"apect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"speechForm": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "SINGULAR",
"person": "PERSON_UNKNOWN",
"proper": "PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
"dependencyEdgeHeadTokenIndex": 7,
"dependencyEdgeLabel": "NSUBJ"
"lemma": "Google"
}
],
"language": "en"
}
2. Sentiment analysis
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.8
},
"language": "en",
"sentences": [
{
"text": {
"content": "Enjoy your vacation!",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.8,
"score": 0.8
}
}
]
}
Flattened:
{
"magnitude": 0.8,
"score": 0.8
"language": "en",
"sentences": [
{ # record
"content": "Enjoy your vacation!",
"beginOffset": 0
"magnitude": 0.8,
"score": 0.8
}
]
}
3. Entity analysis
{
"entities": [
{
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": {
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
}
}
...
],
"language": "en"
}
Flattened:
{
"entities": [
{ # record
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": { # as a map<string,string> since fields are dynamic. Do not flatten. Looks better
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{ # record
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
"type": "TYPE_UNKNOWN"
}
]
}
}
...
],
"language": "en"
}
4. Entity analysis
{
"entities":[
{
"mentions":[
{
"sentiment":{
"magnitude":0.9,
"score":0.9
},
"text":{
"beginOffset":7,
"content":"R&B music"
},
"type":"COMMON"
}
],
"metadata":{
},
"name":"R&B music",
"salience":0.5597628,
"sentiment":{
"magnitude":0.9,
"score":0.9
},
"type":"WORK_OF_ART"
}
],
"language":"en"
}
Flattened:
{
"entities":[
{ # record
"mentions":[
{ # record
"magnitude":0.9,
"score":0.9
"beginOffset":7,
"content":"R&B music"
"type":"COMMON"
}
],
"metadata":{ # as a map<string,string> since fields are dynamic. Do not flatten. Looks better
},
"name":"R&B music",
"salience":0.5597628,
"magnitude":0.9,
"score":0.9,
"type":"WORK_OF_ART"
}
],
"language":"en"
}
6. Classify content:
{
"categories":[
{
"confidence":0.61,
"name":"/Computers & Electronics"
},
{
"confidence":0.53,
"name":"/Internet & Telecom/Mobile & Wireless"
},
{
"confidence":0.53,
"name":"/News"
}
]
}
Does not change.
Created in 2020 by Google Inc.