Workflow Diagnostics Tool
Status: INCOMPLETE
This page is work in progress
Motivation
If a program takes a longer time than anticipated (rogue workflows), we can pinpoint where the problem is, instead of going over a lot of unnecessary logs. As a System Admin, this would be useful to find which jobs were causing delays in times. As a developer, it will be useful to see what parts of the workflow took how much time, and trying to parallelize/optimize those aspects of the workflow. From a scheduling standpoint, a user can figure out the duration of the average/ worst case runs and set the frequencies of the jobs accordingly. Setting a common standard to show metrics of MR jobs/ Spark at the workflow level will help users understand and analyze their runs better.
User Stories
Number | User Story | Priority |
1 | User wants to find what runs of a workflow have experienced delays in meeting SLA | H |
2 | User wants to see what are the stats for a workflow | H |
3 | User wants to know what were the reason behind the delay of certain action/run | H |
4 | User wants to make future resource allocation decisions based on historical performance of past runs | M |
5 | User wants to see a common metric across various action types to make things look uniform | L |
6 | User wants to see common aggregations across all runs of a workflow (see below) | H |
7 | User wants to see statistics across actions in a workflow | M |
Design
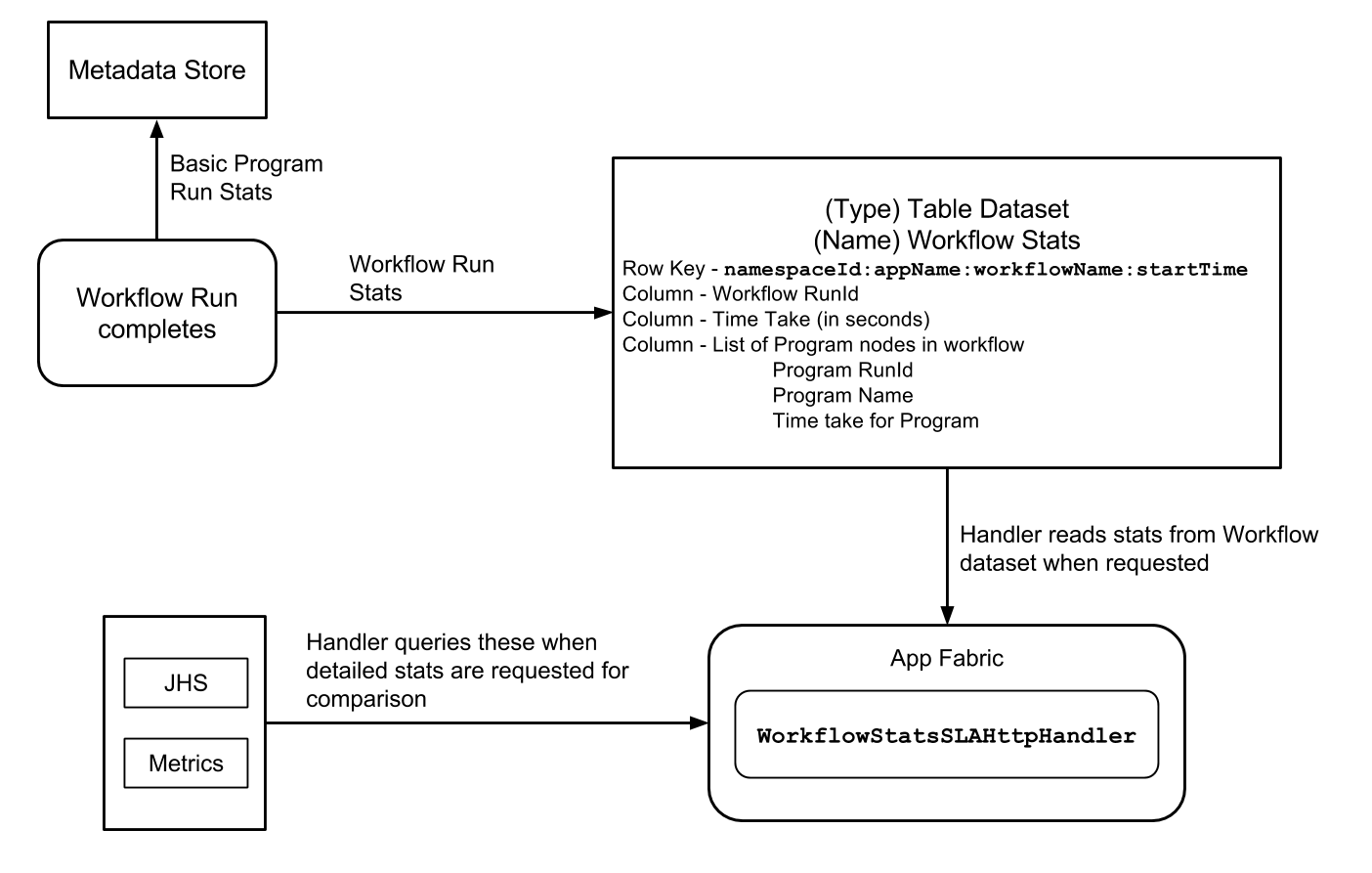
WorkflowSlaStatsHandler is a part of the App-Fabric
On calling the /stats endpoint
We retrieve a list of all completed Workflow Runs from the Workflow Stats Dataset within the provided time range.
Using this list we calculate the statistics(percentiles requested by user) for a workflow and all its nodes and then return those stats to the user.
The second endpoint gives the user the ability to dig deeper into investigating what the cause was for runs to take unusually long. The /stats endpoint will, for example, return a list of all run-ids that were greater than the 99th percentile. Using those run-ids, we can dig deeper into analyzing and seeing the difference of a particular run against the normal runs of a workflow.
This endpoint provides the user the ability to configure at fine-grained level, the count of runs before and after the current run of interest and also sampling time interval. Let's say the user made a request with count=3 and time_interval=1day, we would return 7 run_ids in the result, 3 runs before the interested run and 3 after, each evenly spaced at 1 day interval.
The details will be collected from MRJobInfoFetcher, MetricsStore and MDS.
FUTURE IMPROVEMENT: Naively, this will just return a evenly spaced sampling from the interval but we could optimize it to provide those results from the range which are close to the average so that the user does not end up seeing only abnormal runs.
The third endpoint gives us the ability to compare 2 runs of a workflow side-by-side. This ability comes in handy when the user has 2 runs, one which is normal, and the other which is an outlier and compare them to see why the outlier run turned out that way.
Workflow Analytics Service
This service should be a system service, with the ability to be turned on or off as the user desires.
Handler Endpoint | Response | Desc |
app/{app-id}/workflows/{workflow-id}/statistics?start={st}&end={end}&percentile={p1}&percentile={p2}&percentile={p3} | { "startTime": 0, "endTime": 1442008469, "runs": 4, "avgRunTime": 7.5, "percentileInformationList": [ { "percentile": 80.0, "percentileTimeInSeconds": 9, "runIdsOverPercentile": [ "e0cc5b98-58cc-11e5-84a1-8cae4cfd0e64" ] }, { "percentile": 90.0, "percentileTimeInSeconds": 9, "runIdsOverPercentile": [ "e0cc5b98-58cc-11e5-84a1-8cae4cfd0e64" ] }, { "percentile": 95.0, "percentileTimeInSeconds": 9, "runIdsOverPercentile": [ "e0cc5b98-58cc-11e5-84a1-8cae4cfd0e64" ] }, { "percentile": 99.0, "percentileTimeInSeconds": 9, "runIdsOverPercentile": [ "e0cc5b98-58cc-11e5-84a1-8cae4cfd0e64" ] } ], "nodes": { "PurchaseHistoryBuilder": { "avgRunTime": "7.0", "99.0": "8", "80.0": "8", "95.0": "8", "runs": "4", "90.0": "8", "type": "MapReduce" } } } | returns basic stats about the workflow program across all runs. This will help us in detecting which jobs might be responsible for delays. |
app/{app-id}/workflows/{workflow-id}/runs/{run-id}/stats?start={st}&end={end}&liimt={limit}&interval={interval} | { "startTimes": { "1dd36962-58d9-11e5-82ac-8cae4cfd0e64": 1442012523, "2523aa44-58d9-11e5-90fd-8cae4cfd0e64": 1442012535, "1873ade0-58d9-11e5-b79d-8cae4cfd0e64": 1442012514 }, "programNodesList": [ { "programName": "PurchaseHistoryBuilder", "workflowProgramDetailsList": [ { "workflowRunId": "1dd36962-58d9-11e5-82ac-8cae4cfd0e64", "programRunId": "1e1c3233-58d9-11e5-a7ff-8cae4cfd0e64", "programRunStart": 1442012524, "metrics": { "MAP_INPUT_RECORDS": 19, "REDUCE_OUTPUT_RECORDS": 3, "timeTaken": 9, "MAP_OUTPUT_BYTES": 964, "MAP_OUTPUT_RECORDS": 19, "REDUCE_INPUT_RECORDS": 19 } }, { "workflowRunId": "1873ade0-58d9-11e5-b79d-8cae4cfd0e64", "programRunId": "188a9141-58d9-11e5-88d1-8cae4cfd0e64", "programRunStart": 1442012514, "metrics": { "MAP_INPUT_RECORDS": 19, "REDUCE_OUTPUT_RECORDS": 3, "timeTaken": 7, "MAP_OUTPUT_BYTES": 964, "MAP_OUTPUT_RECORDS": 19, "REDUCE_INPUT_RECORDS": 19 } } ], "programType": "Mapreduce" } ] } | get stats for each stage for a run of a workflow and compares it to + or - count runs that came in the time window provided. The time interval specified allows the previous or next runs to space out in give range. Reference - p{x} is x runs before the current run n{x} is x runs after the current run |
app/{app-id}/workflows/{wf-id}/runs/{run-id}/compare?other-run-id={run-id-2} | [ { "programName": "PurchaseHistoryBuilder", "workflowProgramDetailsList": [ { "workflowRunId": "14b8710a-58cd-11e5-98ca-8cae4cfd0e64", "programRunId": "14c9d62b-58cd-11e5-9105-8cae4cfd0e64", "programRunStart": 1442007354, "metrics": { "MAP_INPUT_RECORDS": 19, "REDUCE_OUTPUT_RECORDS": 3, "timeTaken": 7, "MAP_OUTPUT_BYTES": 964, "MAP_OUTPUT_RECORDS": 19, "REDUCE_INPUT_RECORDS": 19 } }, { "workflowRunId": "e0cc5b98-58cc-11e5-84a1-8cae4cfd0e64", "programRunId": "e1497ad9-58cc-11e5-9dfa-8cae4cfd0e64", "programRunStart": 1442007268, "metrics": { "MAP_INPUT_RECORDS": 19, "REDUCE_OUTPUT_RECORDS": 3, "timeTaken": 8, "MAP_OUTPUT_BYTES": 964, "MAP_OUTPUT_RECORDS": 19, "REDUCE_INPUT_RECORDS": 19 } } ], "programType": "Mapreduce" } ] | Compare 2 runs of a workflow side by side |
Design:
Table
rowkey : {ns_appId_workflowId_startTime}
col : runid
col: time_taken
col: node_stats example: [{ program_name, runId, timeTaken_seconds}, { program_name, runId
timeTaken_seconds}]
CDAP Metrics System
All the metrics from Spark are emitted to the CDAP Metrics System
User metrics and job-level metrics for Map-reduce job are emitted to CDAP Metrics System
Metrics for custom-action and conditions nodes aren’t available right now, but they will be emitted to CDAP Metrics System when implemented
CDAP Metrics System has metrics aggregated by multiple resolutions {seconds, minutes, hours} - when querying for long-running batch program metrics , it will be useful and efficient to use minutes or hours resolutions to get higher-level details and reduces data points.
since we depend on CDAP Metrics System heavily, CDAP should be operational with the metrics.processor and metrics.query services running.
MDS
MDS stores run-records of program containing information
<app-name> <prg-type> <prg-name> <run-id> <start-time> <stop-time> <final-status> <limit>
Use the store directly to access the run records.
Assumptions
CDAP Services are running.
Dataset service is running.
User Interface
curl calls
Implementation Plan
Create a dataset that stores completed workflow runs
Implement the handler
/stats endpoint
/runs/{run-id}/stats endpoint
/compare endpoint
Limitations
JHS stores data for 7 days only by default. Data that is older is not stored. In that case, we might have to return CDAP metrics for MR jobs if older runs are returned.
New workflow runs can only be added to this dataset at this point. There is no way to backfill the workflow stats table based on historical runs.
Created in 2020 by Google Inc.