/
CDAP Cloud 5.x
CDAP Cloud 5.x
- Sree Raman
Owned by Sree Raman
Introduction
As of release 4.x, a CDAP instance is tightly bound to run jobs on a single Hadoop cluster. The resources that are needed to run user programs (Mapreduce, Spark, etc) and the resources needed by CDAP for orchestration is bound to the same Hadoop cluster. This approach requires a single long lived instance of the cluster that does not fit into the economies for certain use cases especially on the Cloud. This wiki documents the use cases and high level areas for re-architecting CDAP for Cloud.
User Stories
- Dynamic workloads
- Data architect wants to create a data lake on ADLS by collecting various data from Database, SFTP sites, and Redshift on a periodic basis. The data lake needs to be refreshed with new data on a daily basis. The scale of data that needs to refreshed is around 25 GB per day and will increase over time. The solution to refresh the data in ADLS should use the resources optimally (i.e., use the compute resources as needed) and should scale for future workloads.
- ETL developer wants to build a compute data analytics of the data on data lake. The data is landed into the data lake every day at mid night UTC. The analytics job processes 1TB of data and has to be available at 5am UTC. There are no other jobs that requires this massive scale and the solution designed should reduce the total cost of ownership for the analytics job.
- Data scientist wants is tasked with building a new model for the recommendation system. The model building requires experimentation of large datasets on the data lake and requires a large compute resource for a day. The current production clusters that builds older models does not have enough resources for this "one-off" experiment.
- Reusing Hadoop cluster resources
- Data scientists wants to develop data models using compute resources of an existing cluster, but does not have access to install CDAP on the cluster.
- Operational Metadata (Metrics, Logs, Lineage, Audit)
- ETL developer wants to have access to all the operation logs and metrics for the data pipeline to diagnose and identify any faulty aspects of the running pipeline
- ETL developer wants to have access to all the logs and metrics of the pipelines that was run in the past
- Security architect wants to know which Cloud's compute resource was used for a given run of the pipeline
- Security architect wants to have an audit trail of the pipeline that is orchestrated on the Cloud
- Security architect wants to know in a lineage graph for various runs, which compute resource was used
- Security
- Security architect wants to restrict users based on roles and enable only devops role to run data pipelines that uses cloud resources to to update the data lake. The authorization policies are configured on sentry or ranger on-premise.
- Security architect wants to restrict users from creating profiles for different Cloud environments
High Level Capabilities Required
Definitions:
- Orchestration Plane: Set of CDAP system services that is responsible for scheduling, configuring, and managing user application lifecycle. Orchestration plane is long lived and will manage the runtime plane.
- Runtime Plane: Individual user programs that does a specific task ex: read from Database and populate S3 bucket. Runtime planes are transient for the lifecycle of the program (ex: Data pipelines, Mapreduce/Spark jobs)
- Metadata Plane: Aggregates and index all metadata - technical, business and operational metadata across CDAP runtime
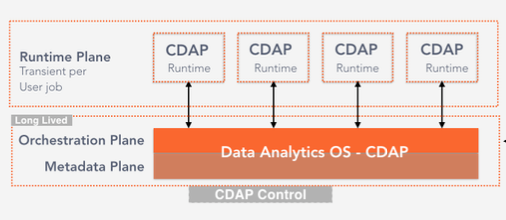
Capabilities:
- Provisioning Mechanism
- Provisioning resources on the cloud using a Java based provisioner
- Runtime and Orchestration plane separation
- Data store and API to manage Cloud credentials
- Dataset Abstractions
- User Interface
Roadmap
- 5.0
- Separation of Orchestration, Metadata and Runtime planes
- Provisioning resources on EMR
- Provisioning Kubernetes (TBD)
- Cloud credential store and APIs
- Orchestrating batch pipeline using MapReduce engine on the EMR
- Operational metadata integration
- User experience for managing profiles, providing profiles to data pipelines
- 5.1
- Provisioning on other cloud
- Reducing footprint on HBase usage for operational needs
- Enforcing security for profile creation
- 5.2
- Separating out Transactions (TBD)
- Support for non pipeline jobs (TBD)
Related content
Compute Cloud Support
Compute Cloud Support
More like this
Decoupling CDAP System Storage from Hadoop
Decoupling CDAP System Storage from Hadoop
More like this
CDAP
More like this
CDAP Datastore SPI Design
CDAP Datastore SPI Design
More like this
Introduction to CDAP
Introduction to CDAP
More like this
CDAP Microservices Guide
CDAP Microservices Guide
More like this
Created in 2020 by Google Inc.