Authorization Design improvements (WIP)
Checklist
- User Stories Documented
- User Stories Reviewed
- Design Reviewed
- APIs reviewed
- Release priorities assigned
- Test cases reviewed
- Blog post
Introduction
Currently, when we load the privileges for a principal in master's cache it remains there forever as the cache expiry defaults to a higher value than the cache refresh interval. As the number of entities and users grow the cache size grows along with it and causes a lot of memory pressure. The cache is currently not bound by size. The master runs a proxy service that all other containers talk to using the RemotePrivilegeFetcher to get all the privileges for a principal. Once a container receives the privileges for a principal it caches it forever as well.
There a couple of reasons for keeping the cache in the master.
- The typical access pattern for Sentry is to whitelist a set of users whom the Sentry service will accept requests from. This list generally contains service users and not end users. Following this pattern "cdap" should be whitelisted in Sentry and all requests to Sentry should be made as "cdap".
- When an application is started, multiple containers could try to fetch the privileges for the same principal. Fetching the data from Sentry for each of these calls would be costly and greatly increase the program startup time.
So, master fetches privileges from Sentry and caches it and all the containers get it from master and cache it locally.
The way the cache is loaded is Apache Sentry specific and relies on a listPrivileges call that lists all Privileges for a principal. Other Authorization providers, e.g. Apache Ranger, may not have this api.
We also have a delay between when an entity is created and when the privileges for it make it down to the container. This is dictated by the cache refresh rate.
Goals
- Make the caching model more scalable. It should be able to handle hundreds of thousands of privileges.
- Refactor the code so that it is easy to support other authorization providers specifically Apache Ranger.
User Stories
As a CDAP admin, I would like to authorize the users who can access the various CDAP entities, I would like to do that at a higher level (e.g. namespace) and any users who have access at that level should have the same access on all entities under that.
- As a CDAP admin, I would like to have a finer grained control over authorization and I would like to explicitly authorize users for each CDAP entity.
- As a CDAP admin, I would like to control the privileges granted on a new entity.
Design
Following are the key principles for the caching design, based on the goals above.
- Scalable: must be able to support hundreds of thousand of entities across namespaces and for a large number of principals.
- Minimize calls to external service as the could be costly.
- Should efficiently handle the case where multiple containers are launched for the same app and there is a spike in authorization requests.
- Should be able to support different authorization providers, e.g. Apache Sentry, Apache Ranger, and Amazon IAM etc.
- Minimize the increase in complexity of creating a new Authorization extension.
- Aim to provide consistent performance for different use cases.
The cache will be changed from Principal -> Map<EntityId, Set<Action>> to <Principal, EntityId> -> Set<Action> to reduce caching unnecessary privileges in case the user has a lot of privileges but only a few of them are being used at one time. The cache will also not be refreshed constantly but only loaded in case of a miss. The entries will have configurable expiry time.
Following are the different approaches that could be taken. I prefer the third approach as that would be most suitable for adding new authorization providers later. It also simplifies the CDAP side interfaces and makes it more agnostic to the Authorization provider.
Here is a performance comparison graph published by Apache Kafka
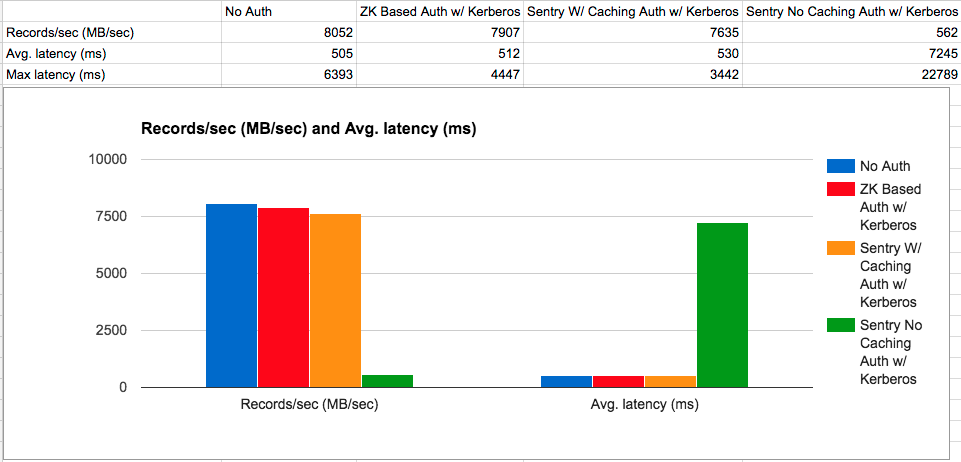
Following are some of the approaches that could be taken. Approach #3 provides the most coverage for our requirements and will also reduce the work required for future extensions.
Approach
Approach #1
The reason containers need to keep refreshing their privilege cache is because they need to know about any changes to the policies i.e., if new privileges were granted to the principal or revoked from them. Since the containers refresh their caches from the master, we need to cache the privileges at the master too because we don't want to fetch the privileges from Sentry on every refresh call from the containers. One way to avoid that is to cache every thing for a principal on a container and any updates to the policy is pushed to the containers. If the containers get updated every time there is a policy change for the principal that the container is interested in they won't need to refresh their caches and we can avoid keeping a cache on the master for refreshes. Master would still need to cache the privileges to handle the spike in requests from multiple containers when a new application is launched but the expiry time in this case could be lower and we don't need to keep refreshing it.
In this approach, all the policy changes would need to be intercepted and pushed to the containers using TMS. This is possible for sentry as the policy changes only happen through CDAP CLI and our Hue plugin.
Pros:
- Cache size in master can be limited
- Containers don't need to keep refreshing their cache. This would reduce a lot of network traffic in a cluster with a large number of containers.
Cons:
All policy changes need to be intercepted
This approach would not work for Apache Ranger as the policy changes there are done through RangerAdmin and there is no way to intercept it from inside CDAP.
Approach #2
The caching model can be changed from Principal -> Map<EntityId, Set<Actions>> to <Principal, EntityId> -> Set<Actions>. All cache misses will trigger and update from Sentry. Caches on both master and other containers will be size limited. In this approach, when we have a cache miss for a principal and entity combination we will fetch privileges from the authorization provider. In case of Sentry this would be done by calling listPrivileges, which would fetch all privileges for the principal and then we break it by principal and entity combination and load the cache. In case of another authorization provider which supports querying by a principal and entity combination, we can simply fetch the requested privilege. This approach requires minimal change to existing code.
Pros
- Only the privileges for the combination of Principal and entities in use will be cached.
- Fewer changes required
Cons
- Many more calls to the authorization provider.
- More cache misses as the key is now narrower
- Could have double caching for extensions that do their own caching
Approach #3
Apache Ranger's plugin has it's own cache. It uses local files to cache policies and polls the server at a configurable interval to see if there are any new policy changes. A possible approach could be to let the Authorizer handle its own caching and the only interaction between CDAP and the extension are policy management and policy enforcement. With this approach CDAP won't have to worry about what API's the backend provider has for accessing privileges and the interaction could be a lot more standardized. All provider specific details would be handled by the provider specific extension.
The Authorizer interface does not need to be changed. We can add a cache implementation to the AbstractAuthorizer. The enforce call will hit the cache and if the Principal, Entity combination is in the Cache then the request will be satisfied there or the cache will be populated by that extension's loader, which in Sentry's case could be the same listPrivilege mechanism that we are doing now but for Ranger, for example, it could be a call to Ranger with a isAccessAllowed method call.
Pros
- Less work to support Apache Ranger
- CDAP is more agnostic to different authorization providers
- Removes need to keep refreshing cache
- No need to have PrivilegeFetcher interface, Authorizer handles all authorization work
Cons
- More work required than Approach #2
- Many more calls to the authorization provider.
- More cache misses as the key is now narrower
Caching on Master
This approach will still have a cache in the master process. To reduce the size of the cache and stop it from causing a memory issue we can do the following
- Reduce master cache entry timeout - Caching on master is primarily required when we launch a new job for example, and that launches a large number of containers. We don't want the authorization requests from all these containers to cause a call to Sentry. These authorization requests will with high probability be bunched together at the launch, so having a cache at master will be very helpful but we don't need to hold on to that entry for a long time. So, having a smaller timeout for master will be helpful. (Probably 10 seconds)
- Change grant to grant only required privileges - Since we support hierarchical privileges we don't need to explicitly grant the privileges that the user already has on an ancestor. e.g. a user needs WRITE on a namespace to be able to create a stream. When we create a new entity we grant all privileges on that to the creating user. So, in this case we grant WRITE on the stream again to the user. We can make the grant smarter to only grant the privileges that the user does not have. This will make it difficult to revoke privileges on individual entities but the assumption is that the general use-case would be as following, a user joins a group, they get all the privileges that the group has. When they create an entity they get all the privileges on the entity that they don't have on the namespace. We can make the list of privileges to the creator a configurable option. When the user leaves the group it should be easy to revoke all privileges for that user. A big drawback of this is that there will be no way to revoke privileges for a user from an entity down the entity hierarchy eg. if the user already has read on the namespace then he won't be granted explicit read on the stream and because of this there will be no way to revoke read access for that user on that stream.
- Change the cache key to be <Principal, Entity> so that we only cache the privileges that we actually need.
- Limit the size of the cache
About Revoke
We can, perhaps, have a way to store DENY. This will let us keep the revoke by entering a DENY for an action on an action for a user on an entity.
Caching on service containers
Since service containers impersonate users they need to cache privileges for multiple principals. Items 2, 3, and 4 under "Caching on Master" will be applicable for service containers too. Service containers can have a lower cache entry timeout than program containers.
Caching on program containers
Since program containers are owned by a single principal, the memory pressure is far less here. With the cache key being <Principal, Entity> and reduction in the number of privileges due to smarter grants will alleviate any issues. We will still limit the cache size for safety.
Another option for this is for the master to fetch all the logs for the principal that will own the containers and ship that as a file to the launched containers. Instead of the containers having to pull changes to the policy, Master will have to keep polling for changes to the policies and push the changes to the appropriate containers based on the principal. The drawback of this approach is that the master will need to keep polling for changes similar to what we do today.
Things to do
- Change privilege cache to <Principal, Entity, Action> -> Boolean: This is so that we can avoid using the list api and instead cache on the enforce call (4.2.0)
- Remove listPrivileges (4.2.0)
- Configuration for extension cache timeout (4.2.0)
- Change the grant and revoke commands
- Remove auto-granting of privileges on creation - This can be controlled through a configuration. Initially it can be a system wide configuration like a umask but can be further enhanced to be per-namespace.
- Add a configuration to selecting privilege propagation (4.2.0)
- Stop auto refreshing the cache and load cache in case of a miss (4.2.0)
- Move cache to the extensions (4.2.0)
- Change the Sentry extension to not use listPrivileges and find a way to load the cache in a more fine grained way (e.g. limit it to the principal and entity, instead of getting all the privileges)
- Try SimpleCacheProviderBackend as the authorization backend (4.2.0)
Hierarchical Privileges
In previous releases the privileges were hierarchical, i.e., if a user has a privilege to perform an action on an entity then they can perform that action on all the children of that entity. This is handled by the following code in DefaultAuthorizationEnforcementService
if (entity instanceof ParentedId) {
if (doEnforce(((ParentedId) entity).getParent(), principal, actions, false)) {
return true;
}
}
This makes revoking privileges complicated to reason about. What happens if someone has READ on a namespace and READ on a dataset and we revoke READ on the dataset?
This will be changed and a policy configuration will be introduced, which will allow the user to either have the privileges propagate downwards, i.e., if the user has READ on a namespace then they have READ on everything inside that namespace, or the user can choose to not have the privileges propagate and in this case the user also needs privileges on the entity to be able to perform action on that.
Automatically granted privileges
All privileges on an entity are automatically granted to the user creating the entity. This was done as a convenience so that users can create an entity and begin using it without the need to being explicitly granted permissions on that entity. This will be removed and the privileges granted on a newly created entity will be controlled by a configuration. Initially this will be done at the instance level but can be further improved to be a namespace level mask. With this change, if policy propagation is turned on, the user will be able to access the newly created entity based on what privileges they have on a parent, with policy propagation turned off, the user will need to be granted any privileges that are not defined in the configuration, if needed.
API changes
New Programmatic APIs
New Java APIs introduced (both user facing and internal)
Deprecated Programmatic APIs
New REST APIs
| Path | Method | Description | Response Code | Response |
|---|---|---|---|---|
| /v3/apps/<app-id> | GET | Returns the application spec for a given application | 200 - On success 404 - When application is not available 500 - Any internal errors |
|
Deprecated REST API
| Path | Method | Description |
|---|---|---|
| /v3/apps/<app-id> | GET | Returns the application spec for a given application |
CLI Impact or Changes
- Impact #1
- Impact #2
- Impact #3
UI Impact or Changes
- (Not in 4.2) Ability to manage privileges from the UI will be a major user experience improvement
Security Impact
This will change the way authorization is implemented and will have a major security impact. To properly cover the changes more integration tests will be added. We will also need to update the doc to mention the configuration that controls the privilege propagation as that will impact the security policies. The changes will also have a performance impact when authorization is enabled. Once the implementation is done, performance comparison graphs will be added to this wiki.
Impact on Infrastructure Outages
System behavior (if applicable - document impact on downstream [ YARN, HBase etc ] component failures) and how does the design take care of these aspect
Test Scenarios
| Test ID | Test Description | Expected Results |
|---|---|---|
Releases
Release 4.2.0
Release 4.3.0
Related Work
- Work #1
- Work #2
- Work #3
Future work
Secure the communication between the containers and master so that authorization related messages can not be intercepted or spoofed.
Created in 2020 by Google Inc.