Pipelines present a logical view of your business logic. A single pipeline will break down into one or more Spark jobs. Each job reads data, processes it, and then writes out the data. One common misconception is that each pipeline stage will get processed completely before moving on to the next one. In reality, multiple pipeline stages will get grouped together into jobs based on the structure of the pipeline. More specifically, shuffles and sinks determine how the pipeline will get broken down.
Branches
Pipeline stages are grouped into Spark jobs by starting from a sink and tracing backwards to a source or a shuffle stage. This means that a pipeline with multiple branches will result in multiple Spark jobs. For example, consider the following pipeline with two branches.
The first Spark job consists of the DataGenerator, Wrangler, and Trash stages. You can tell this is the case because the metrics for the first stages will update and complete before the next stages start.
Caching
In the branch example above, even though the DataGenerator source stage is part of two Spark jobs, the number of output records stays at 1 million instead of 2 million. This means the source is not processed twice. This is achieved using Spark caching. As the first job runs, it caches the output of the DataGenerator stage so that it can be used during the second job. This is important in most pipelines because it prevents multiple reads from the source. This is especially true if it is possible to read different data from the source at different times. For example, suppose a pipeline is reading from a database table that is constantly being updated. If both Spark jobs were to read from the table, they would both read different data because they would be launched at different times. Caching ensures that only a single read is done so that all branches see the same data. Additionally, it is desirable for certain sources like the BigQuery source, where there is a monetary cost associated with each read.
Note that Spark performs caching as part of a Spark job. In the example above, it is performed as part of the first job and then used in the second. There is not an initial job that reads the data and stops at the cache point. Cached data is kept for the lifetime of a single pipeline run. It is not persisted across runs.
Data does not always need to be explicitly cached. When a pipeline contains a data shuffle, Spark will keep the intermediate shuffle data around and read from that point on in other jobs when possible. For example, if the example pipeline is modified to include a Distinct plugin before branching, the pipeline does not need to cache the output of the Distinct plugin in order to prevent the source from being recomputed.
The first job would include the DataGenerator, Distinct, Wrangler, and Trash stages.
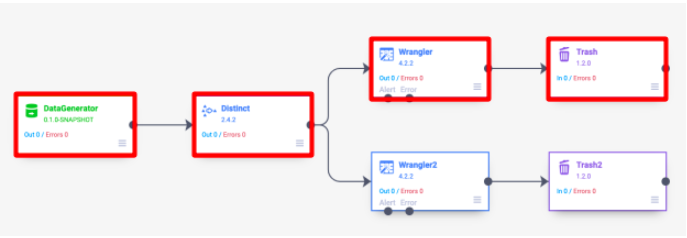
The second would read the intermediate shuffle data used in the first job, execute the post-shuffle part of the Distinct, and execute the Wrangler2 and Trash2 stages.

In CDAP 6.1.3 and earlier, data is cached aggressively to try and prevent any type of reprocessing in the pipeline. Starting from CDAP 6.1.4, data is cached at fewer points, only to prevent sources from being read multiple times. This change was done because caching is often more expensive than re-computing a transformation. In the example above, this means 6.1.3 would cache the output of the Distinct plugin, while 6.1.4 would not, since Spark itself knows it can start from the intermediate shuffle data. However, it does mean that the metrics for the number of output records will be double the number of records processed on each branch, as the post-shuffle work is still computed twice.