Checklist
- User Stories Documented
- User Stories Reviewed
- Design Reviewed
- APIs reviewed
- Release priorities assigned
- Test cases reviewed
- Blog post
Overview
This addition will allow users to see the history of directives made to a column of data.
Goals
User should be able to see lineage information, ie. directives, for columns
Storing lineage information should have minimal/no impact to the wrangler application
User Stories
As a user, I should be able to see the directives applied to a column of data.
As a user, I should be able to see the directives applied to a column of data over any period of time.
- As a user, I should be able to see how any column got to its current state as well as other columns that were impacted by it
As a user, I should be able to add tags and properties to specific columns of data (stretch)
Design
Save directives for each column in AST format after parsing of directives along with necessary information (time, dataset/stream name/id, etc.).
Use TMS to send information to platform.
Unmarshal and store in HBase.
Access to lineage should only be available through the platform
Questions
- How to get source and sink datasets?
- How to ensure this works with multiple transform nodes, even just wrangler nodes?
- How to send and consume data from wrangler to CDAP?
- Does ParseTree have all necessary information for every directive?
Approach
Computing Lineage Approach:
Compute lineage without looking at data by backtracking
Advantages:
- No instance variables added to step classes
- Faster
Disadvantages:
- Requires stricter rule on directives, ie. every rename must give old and new name. See * below for why
*Backtrack starting with columns A,B,C. Previous directive is "set-columns A B C". The directive before that is "lowercase <column>" where <column> is nameOfOwner. No way of knowing what nameOfOwner refers to without looking at data.
API changes
New Programmatic APIs:
TransformStep:
TransformStep is a Java interface that represents a modification done to a dataset by a transform stage.
FieldLevelLineage:
FieldLevelLineage is a Java interface that contains all the necessary field-level lineage information to be sent to the CDAP platform, for transform stages.
WranglerFieldLevelLineage:
Instance should be initialized per wrangler node passing in a list of final columns (output schema) and the name of the wrangler node.
store() takes a ParseTree and stores all the necessary information into lineages.
Stores lineage for each column in lineage instance variable which is a map to ASTs.
Parse Tree should contain all columns affected per directive.
Labels:
- All columns should be labeled one of: {Read, Drop, Modify, Add, Rename}
- Read: column's name or values are read. Including reading values and modifying. ie. "filter-rows-on..."
- Drop: column is dropped
- Add: column is added
- Rename: column's name is replaced with another name
- Modify: column's values altered and doesn't fit in any of the other categories, ie. "lowercase"
For Read, Drop, Modify, and Add the column and associated label should be something like -> Column: Name, Label: add.
For Rename the column and associated label should be something like -> Column: body_5 DOB, Label: rename. // Basically some way of having both names, currently using a space. Old/new for rename. Swap example: A B, Label: rename and B A, Label: rename. Both the old & new names should be part of the information being sent somehow.
For Read, Modify, and Add there is another option; instead of column name can return {"all columns", "all columns minus _ _ _ _ ", "all columns formatted %s_%d"}, along with label. ie. Column: "all columns minus body", Label: add. "all columns" refers to all columns present in dataset after execution of this step. Format string only accepts %s and %d.
For Rename, and Drop this option is not available; must explicitly return name of all columns involved.
**Assumption (can be changed): In ParseTree all columns should be in order of impact. ie. If directive is "copy A A_copy". "A, Label: read" should be before "A_copy, Label: add".
Algorithm visual: Example wrangler application --> lineage --> ASTs for each column


FieldLevelLineageStorageNode:
FieldLevelLineageStorageNode is a Java interface that represents an element being stored in HBase.
These nodes are created and connected in an AST format by FieldLevelLineageStorageGraph.
FieldLevelLineageStorageGraph:
FieldLevelLineageStorageGraph is a Java class that transforms many instances of FieldLevelLineage into a graph of FieldLevelLineageStorageNodes for storage.
One instance of this type should be created per pipeline. Created from many instances of FieldLevelLineage, some graph representation of the pipeline, a mapping between reference names and stage names for sources/sinks, and ProgramRunId.
Visual:

Publishing Lineage Information:
Will be done through new prepareRun() function in the Transform class and new recordLineage(FieldLevelLineage f) function in StageSubmitter interface. Each transform plugin stage will have option to publish field-level lineage.
New REST APIs
| Path | Method | Description | Response |
|---|---|---|---|
/v3/namespaces/{namespace-id}/datasets/{dataset-id}/columns/{column-id}/lineage?start=<start-ts>&end=<end-ts>&maxLevels=<max-levels> | GET | Returns list of directives applied to the specified column in the specified dataset | 200: Successful Response TBD, but will contain a Tree representation |
/v3/namespaces/{namespace-id}/streams/{stream-id}/columns/{column-id}/lineage?start=<start-ts>&end=<end-ts>&maxLevels=<max-levels> | GET | Returns list of directives applied to the specified column in the specified stream | 200: Successful Response TBD, but will contain a Tree representation |
CLI Impact or Changes
TBD
UI Impact or Changes
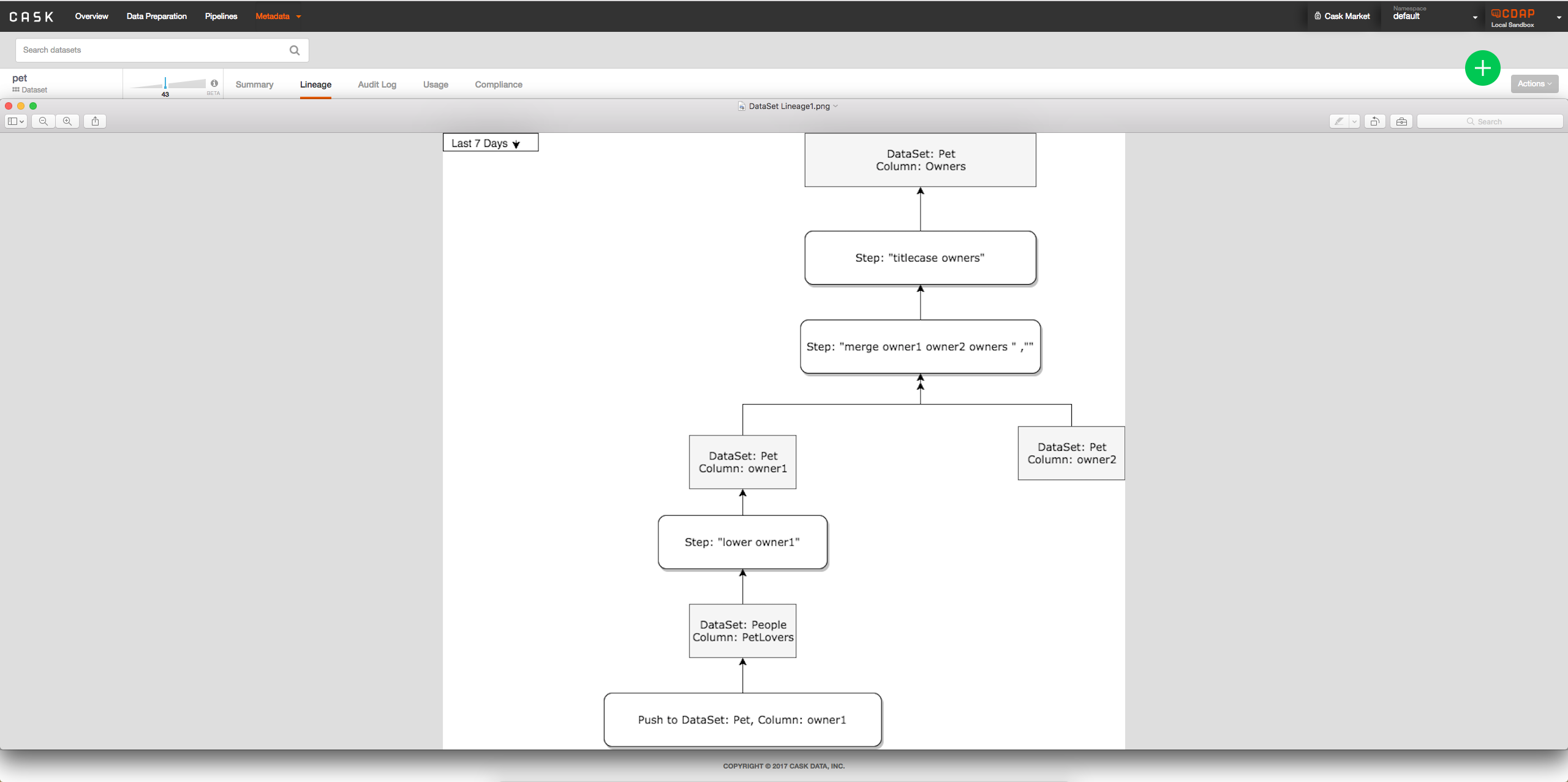
- Option 2: Add interface to metadata table when viewing dataset to see lineage of columns possibly by clicking on column: -> When a column is clicked on will look something like:
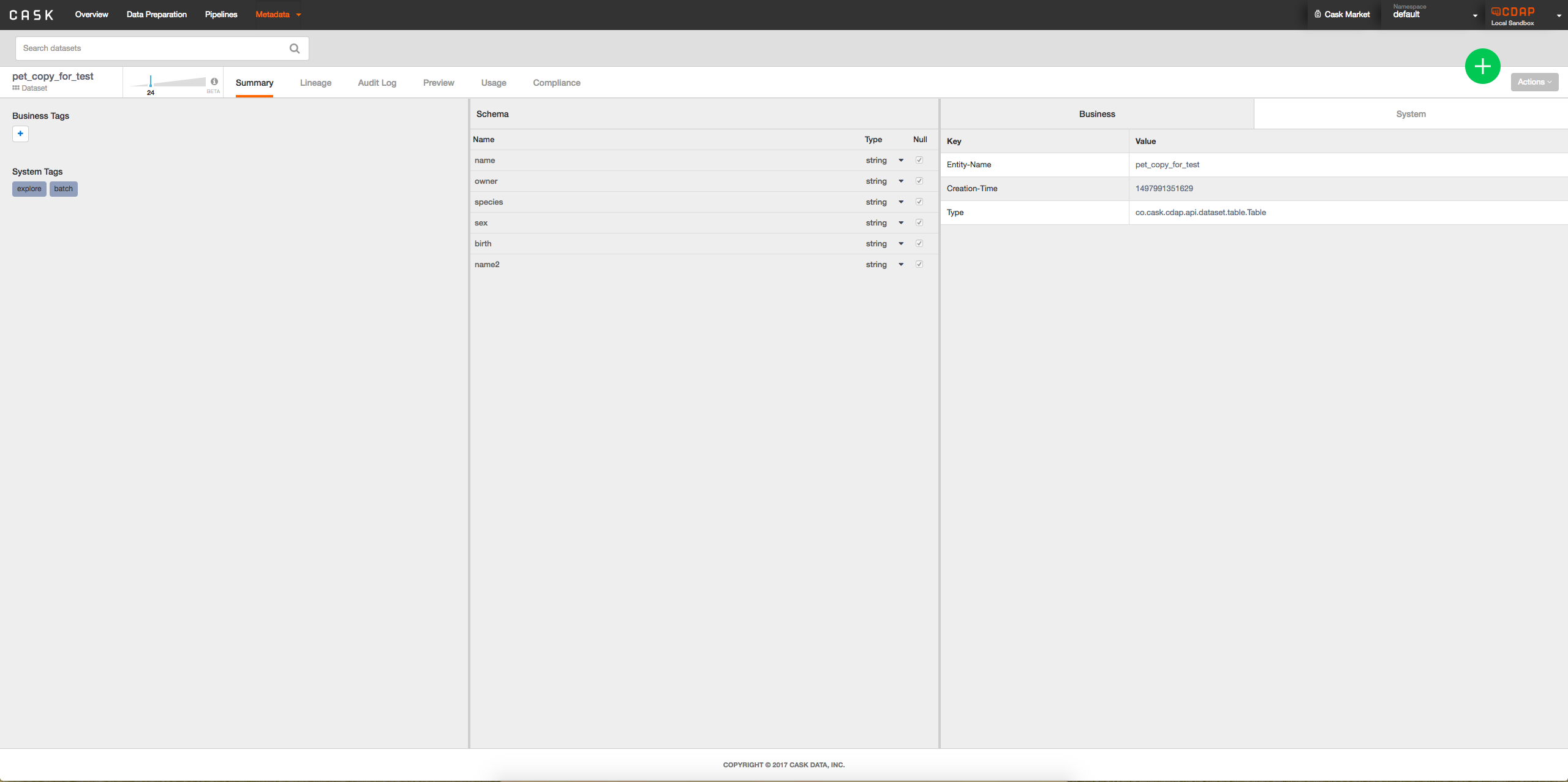 ->
-> 
- Option 2: Show all columns at once directly on lineage tab from clicking on dataset, tab between field level and dataset level:
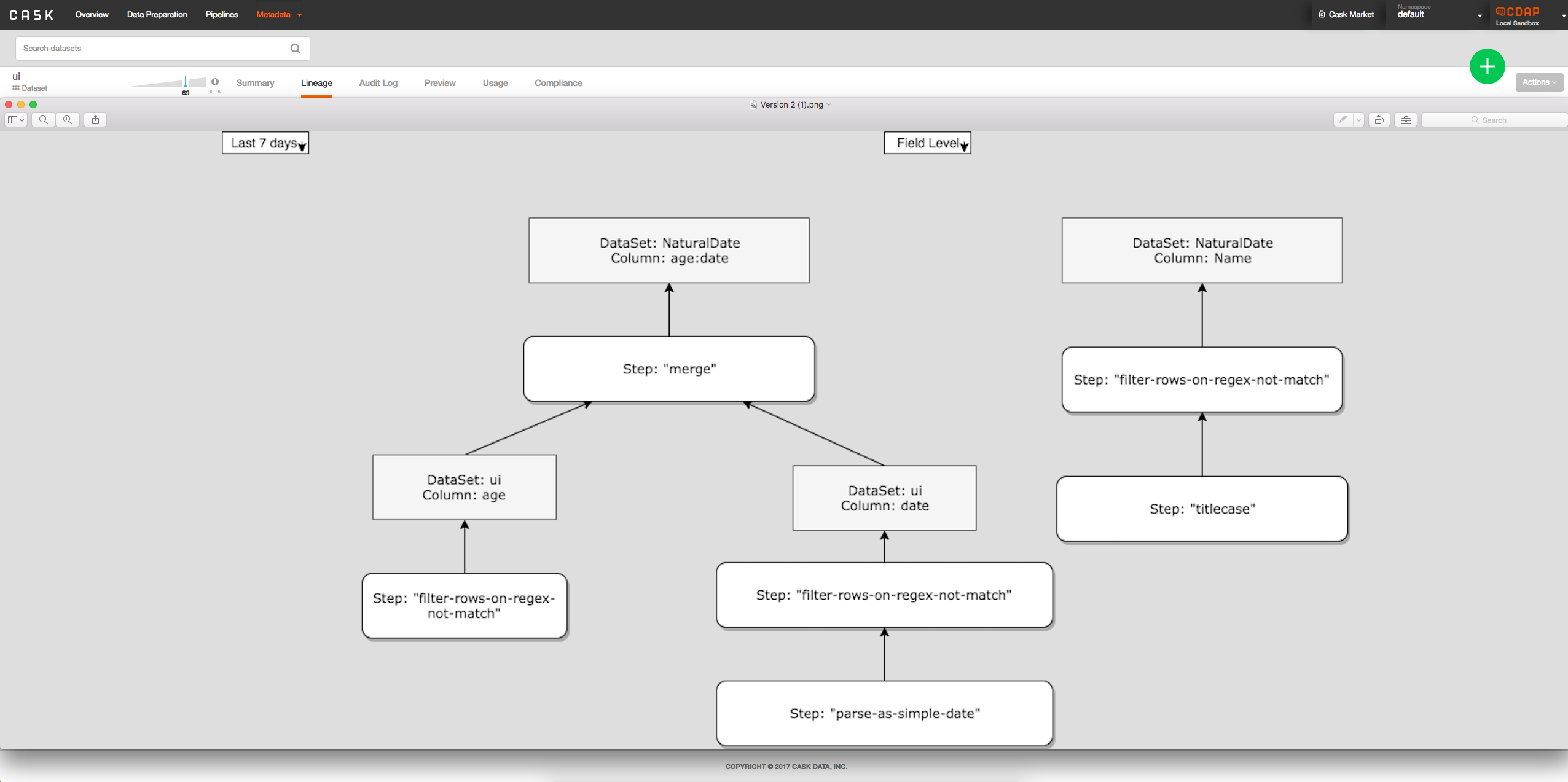
Security Impact
Should be none, TBD
Impact on Infrastructure Outages
Storage in HBase. Key being dataset name + field name + boolean(read/lineage). For each pipeline a node is added to this key; Impact TBD.
Test Scenarios
| Test ID | Test Description | Expected Results |
|---|---|---|
| 1 | Tests all directives | All Step subclasses should be properly parsed containing all correct columns with correct labels |
| 2 | Multiple datasets/streams | Lineages are correctly shown between different datasets/streams |
| 3 | Tests all store() | FieldLevelLineage.store() always correctly stores step |
Releases
Release 4.3.0
Release 4.4.0
Related Work
- Fixing TextDirectives and parsing of directives in general