After you deploy a data pipeline, you can configure the following:
Compute config
Pipeline config
Engine config
Resources
Pipeline alert
ELT pushdown
Compute config
You can change the compute profile you want to use to run this pipeline. For example, you want to run the pipeline against an existing Dataproc cluster rather than the default Dataproc cluster.
Pipeline config
For each pipeline, you can enable or disable Instrumentation. By default, Instrumentation is set to on.
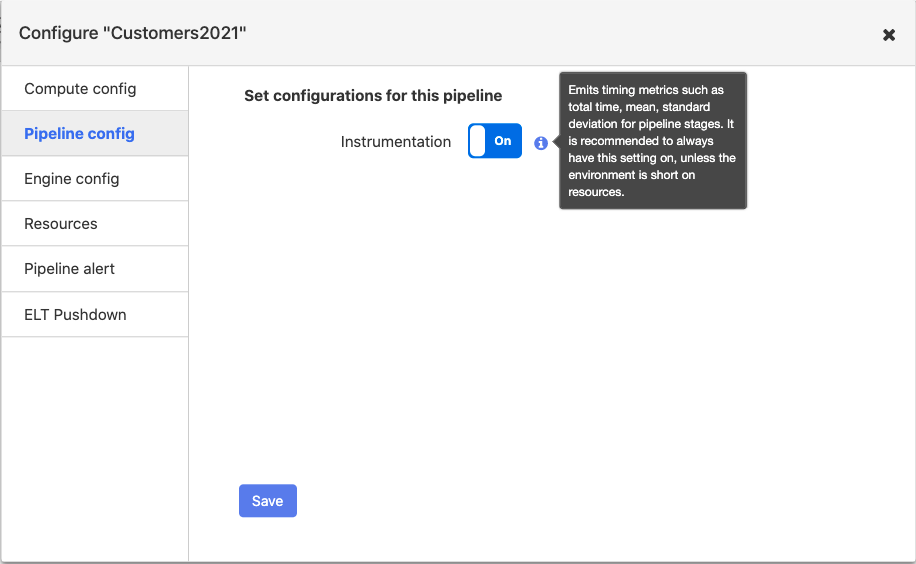
If you enable Instrumentation, when you run the pipeline, it generates metrics for each node. The source, transformation, and sink metrics vary slightly:
Records out
Records in
Total number of errors
Records out per second
Min process time (one record)
Max process time (one record)
Standard deviation
Average processing time
These metrics display on the Metrics tab for each node in a pipeline.
Example of Source metrics
Example of transformation metrics
Example of Sink metrics
It is recommended to always have the Instrumentation setting on unless the environment is short on resources.
Engine config
For each pipeline, you can choose Spark or MapReduce as the execution engine. Spark is the default execution engine. You can also add custom configurations, which allow you to add additional engine configurations. Typically, custom configurations apply to Spark and not as frequently to MapReduce.
Spark engine configs
Here are some examples of custom configurations that are commonly used for Spark:
To improve pipeline performance, add
spark.serializeras the Name andorg.apache.spark.serializer.KryoSerializeras the Value.To workaround a bug in Spark versions prior to version 2.4, enter
spark.maxRemoteBlockSizeFetchToMemas the Name and2147483135as the Value.if you don’t want Spark to retry upon failure, enter
spark.yarn.maxAppAttemptsas the Name and1as the Value. If you want Spark to retry multiple times, set the value to the number of retries you want Spark to perform.To turn off auto-caching in Spark, enter
spark.cdap.pipeline.autocache.enableas the Name, andfalseas the Value. By default, pipelines will cache intermediate data in the pipeline in order to prevent Spark from re-computing data. This requires a substantial amount of memory, so pipelines that process a large amount of data will often need to turn this off.To disable pipeline task retries, enter
spark.task.maxFailuresas the Name and1as the Value.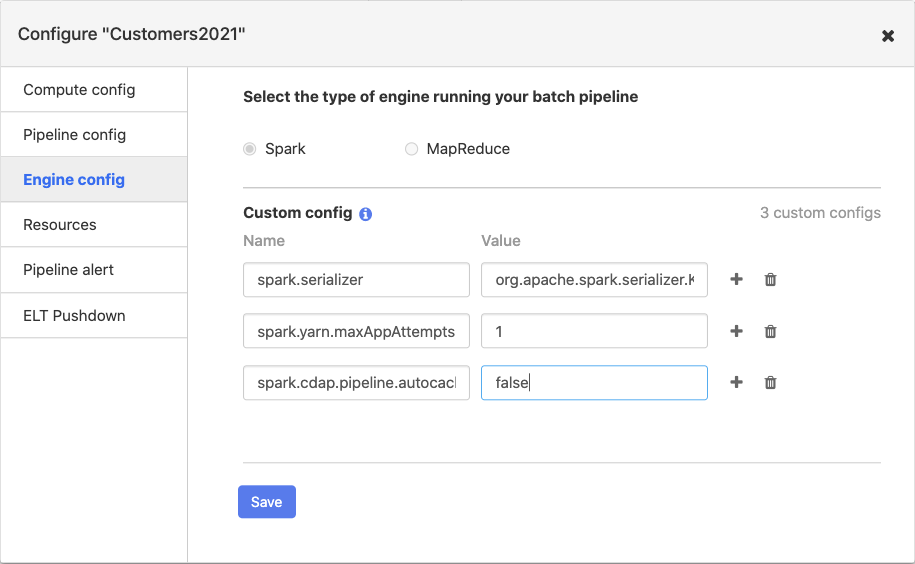
MapReduce engine configs
Here’s an example of a custom configuration used for MapReduce
To disable pipeline task retries, enter
mapreduce.map.maxattemptsas the Name and1as the Value. Add a second config withmapreduce.reduce.maxattemptsas the Name and1as the Value.
Resources
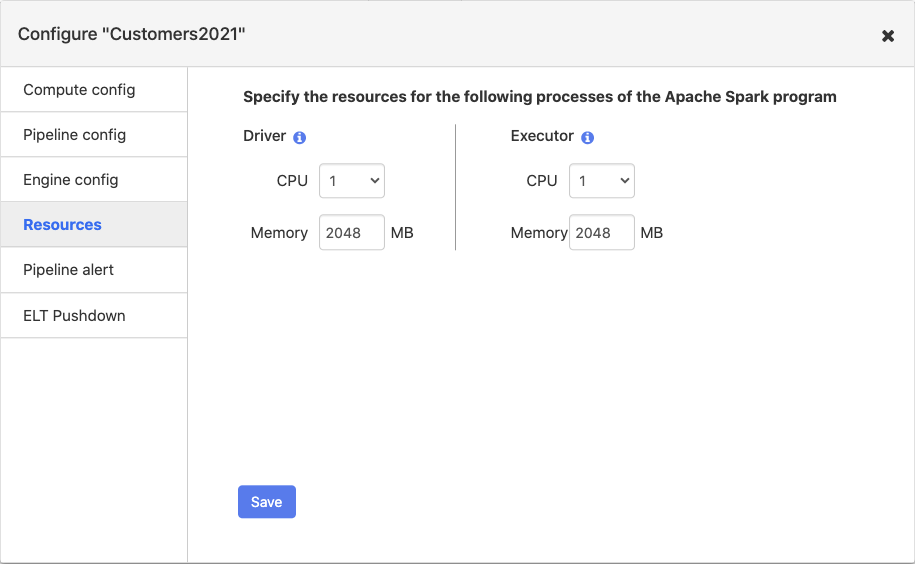
You can specify the memory and number of CPU’s for the Spark driver and executor. The driver orchestrates the Spark job. The executor handles the data processing in Spark.
General tips
Driver resources. Set the driver memory to 8 GB. Increased driver memory is needed for pipelines with large numbers of nodes (20+). If the driver memory is not set high enough, then it results in a driver crash and leads to the following error “Malformed reply from SOCKS server”.
Driver resources. Set the CPU to
1.Executor resources. Set CPU to
1in all CDAP releases up to 6.1.2.Executor resources. Set executor memory to a minimum value of 4 GB (4096 MB). For pipelines that include Joiner transformations and Aggregation transformations that have high cardinality, this configuration should be increased.
Pipeline alert
You can configure CDAP to send alerts and kick off post processing tasks after the pipeline run finishes. You create pipeline alerts when you design the pipeline. After you deploy the pipeline, you can view the alerts, but you cannot add additional alerts or editing existing one. You can choose the type of action you want CDAP to perform when a pipeline run completes, for example:
HTTP alerts are helpful if you use monitoring and alerting systems. These systems get triggered when you call an HTTP endpoint.
Likewise, you might have some database post-processing work that needs to happen after a pipeline run completes. For example, you might have a temporary table that you populate with related data and you need to clean it up after the pipeline runs.
You can choose to send an alert or trigger a post-processing task based on the status of the run:
Completion. The workflow process sends an alert when the pipeline run completes, regardless of whether the pipeline run succeeds or fails.
Success. The workflow process sends an alert when the pipeline run successfully completes.
Failure. The workflow process sends an alert when the pipeline run fails.
You can also create custom plugins to perform specific tasks. There are also various open source plugins that you can add as a pipeline alert.
Note: The Pipeline Studio supports email alerts through SendGrid. Download the SendGrid plugin from the Hub to use it.
To get started adding alerts and post-processing tasks, click Configure > Pipeline Alerts, and then click the + (plus) sign.
Then select the type of post-processing action you want to configure:

Each page has detailed tooltips to help you configure the alert. For more information about pipeline alerts and a complete list of system and user pipeline alerts available, see Batch Pipeline Alerts.
Running a database query
To run a database query when a pipeline run finishes, configure the following properties. You can validate the properties before you save the configuration.
Property | Description |
|---|---|
Run Condition | When to run the action. Must be completion, success, or failure. Defaults to success. If set to completion, the action will be performed regardless of whether the pipeline run succeeds or fails. If set to success, the action will only be performed if the pipeline run succeeds. If set to failure, the action will only be performed if the pipeline run fails. |
Plugin name | Required. Name of the JDBC plugin to use. This is the value of the ‘name’ key defined in the JSON file for the JDBC plugin. |
Plugin type | The type of JDBC plugin to use. This is the value of the ‘type’ key defined in the JSON file for the JDBC plugin. Defaults to ‘jdbc’. |
JDBC connection string | Required. JDBC connection string including database name. |
Query | Required. The database command to run. |
Credentials - Username | User to use to connect to the specified database. Required for databases that need authentication. Optional for databases that do not require authentication. |
Credentials - Password | Password to use to connect to the specified database. Required for databases that need authentication. Optional for databases that do not require authentication. |
Advanced - Connection arguments | A list of arbitrary string tag/value pairs as connection arguments. This is a semicolon-separated list of key/value pairs, where each pair is separated by an equals ‘=’ and specifies the key and value for the argument. For example, ‘key1=value1; ‘key2=value2’ specifies that the connection will be given arguments ‘key1’ mapped to ‘value1’ and the argument ‘key2’ mapped to ‘value2’. |
Advanced - Enable auto-commit | Whether to enable auto commit for queries run by the source. Defaults to false. This setting should only matter if you are using a JDBC driver that does not support the commit call. For example, the Hive JDBC driver will throw an exception whenever a commit is called. For drivers like that, this should be set to true. |
Making an HTTP call
To call an HTTP endpoint when a pipeline run finishes, configure the following properties. You can validate the properties before you save the configuration.
Property | Description |
|---|---|
Run Condition | When to run the action. Must be completion, success, or failure. Defaults to completion. If set to completion, the action will be performed regardless of whether the pipeline run succeeds or fails. If set to success, the action will only be performed if the pipeline run succeeds. If set to failure, the action will only be performed if the pipeline run fails. |
URL | Required. The URL to fetch data from. |
HTTP Method | Required. The http request method. Choose from: DELETE, GET, HEAD, OPTIONS, POST, PUT. Defaults to POST. |
Request body | The http request body. |
Number of Retries | The number of times the request should be retried if the request fails. Defaults to 0 |
Should Follow Redirects | Whether to automatically follow redirects. Defaults to true. |
Request Headers | Request headers to set when performing the http request. |
Generic - Connection Timeout | Sets the connection timeout in milliseconds. Set to 0 for infinite. Default is 60000 (1 minute). |
ELT pushdown
Starting in CDAP 6.5.0, you can enable ELT pushdown to have BigQuery process joins. For more information, see Using ELT pushdown.