Hive 2.0 Support
Error rendering macro 'jira' : Unable to locate Jira server for this macro. It may be due to Application Link configuration.
Introduction
The following design documents:
- The motivation for supporting Hive 2.0.
- A design for how we plan to integration with Hive.
- Considerations we need to make for tradeoffs we are presented during the implementation
Motivation
Hive LLAP (https://cwiki.apache.org/confluence/display/Hive/LLAP) functionality was added in Hive 2.0. If we want to leverage the benefits of LLAP, we can no longer integrate directly with Hive Metastore. Instead, the CDAP-Hive integration will need to happen via HiveServer2.
Additionally, the current integration with Hive leverages classes in Hive that were not meant for public-facing use. Changing the CDAP-Hive integration to happen via HiveServer2 will help ensure compatibility with future Hive versions.
Furthermore, some Hadoop distributions currently ship both Hive1 and Hive2; they may decide to drop support for Hive1 in the future. We should be prepared for this ahead of time.
Design
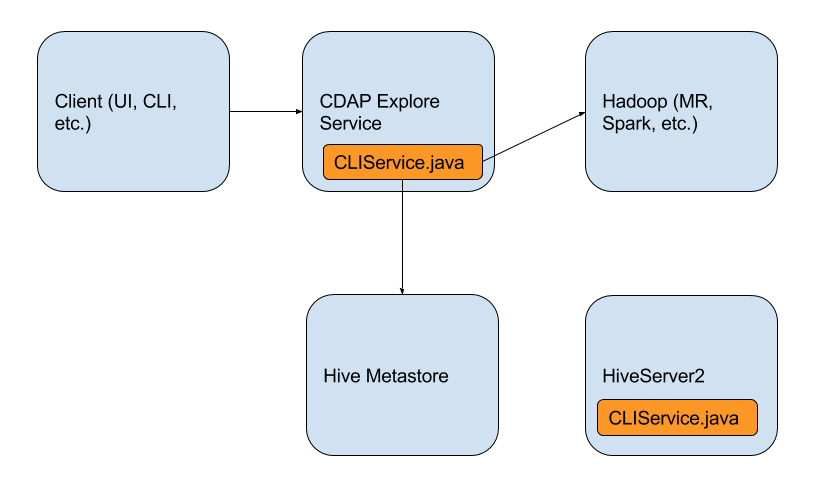
Previous Design Summary
Previously, CDAP explore service would run in a YARN container and this process would be responsible for internally running a CLIService, which is a service that is normally run by the HiveServer2. The CDAP explore service would expose an HTTP endpoint by which users can submit queries, and the explore service would delegate these queries to the CLIService, which would internally use Hive Metastore. This whole process bypasses the HiveServer2 instance, and so the HiveServer2 instance is not a dependency of CDAP.
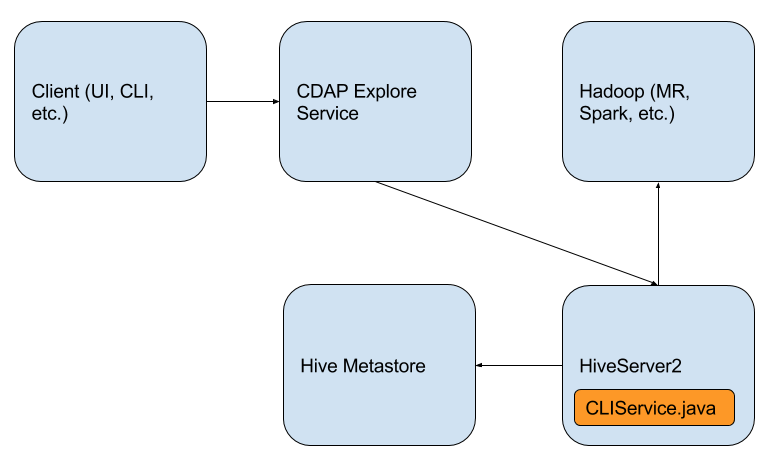
New Design Summary
The proposed design is such that CDAP explore service would continue to run in a YARN container. However, instead of running a CLIService and operating in place of HiveServer2, it will use a JDBC driver to connect to HiveServer2. It would then delegate any queries via JDBC to the HiveServer2. This allows CDAP to use a publicly-facing API of HiveServer2, and allows CDAP to cleanly leverage new features of Hive, such as LLAP.
Setting up the Classpath
Previously, explore service would run CLIService and CDAP had control of how the classpath of this explore service was constructed upon the launching of the explore container. Now, however, the HiveServer2 is a separate service, launched on its own, and so we do not have complete control of its classpath. This brings complications when the HiveServer2 needs to load CDAP classes in order to execute queries against CDAP datasets and streams. Just as an example, some classes that HiveServer2 needs access to are StreamSerDe, HiveStreamInputFormat, DatasetSerde, DatasetSpecification, SystemDatasetInstantiator, Dataset, RecordScannable, ContextManager, among many other dependent classes.
The proposed solution to this is to have a small jar file with enough CDAP classes to bootstrap a classloader that then has all of the necessary CDAP classes. This bootstrapping class would have to localize the CDAP libraries over HDFS. This small jar can be added to either the Hive auxlib, or via the "add jar <jarfile>" statement (source: HiveCommands). However, note that this "add jar <jarfile>" command has a serious bug in many of the Hive versions that we support: https://issues.apache.org/jira/browse/HIVE-11878.
LLAP and Impersonation
The architecture of Hive LLAP shares and caches data across many users. As a result, older file-based security controls do not work with this architecture and doAs (impersonation) is not supported with Hive LLAP. You must use Apache Ranger security policies with a doAs=false setting to achieve secure access via Hive LLAP, while restricting underlying file access so that Hive and other privileged users can access it but unprivileged users cannot. (Source: https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/managing_using_hive.html).
As a result, we must verify that we can still leverage Hive doAs for use cases that don't leverage LLAP, but still wish to have impersonation. For instance, we need to support Apache Sentry as the Authorizer, even if a user wants to use impersonation, without LLAP.
Open Questions
- Will Hive impersonation (doAs) work with the new integration, as long as we do not use LLAP? We'll need to test this, but I believe that it will work.
- How will we propagate CDAP configurations (cdap-site.xml) to the queries running in Hive?
- What will the integration look like on Standalone, where HiveServer2 is not running? Perhaps we will still need to run CLIService for this mode.
- Should we continue to support our existing integration, so that users can switch to the previous implementation, if they have issues with the new HiveServer2 JDBC integration.
Created in 2020 by Google Inc.