Metrics Architecture
Overview
(Diagrams taken from here: cdap-metrics-revised.graffle)
Metrics System components:
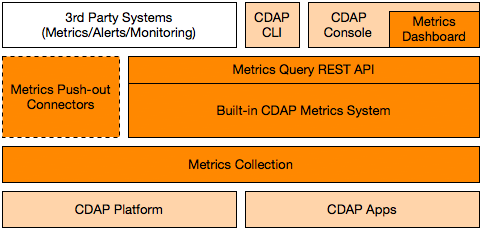
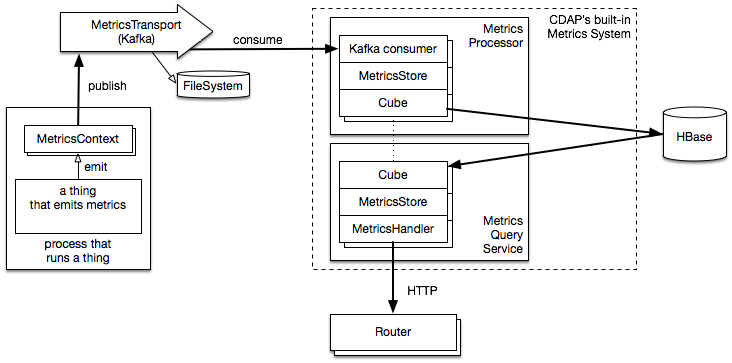
Architecture from 50K feet:
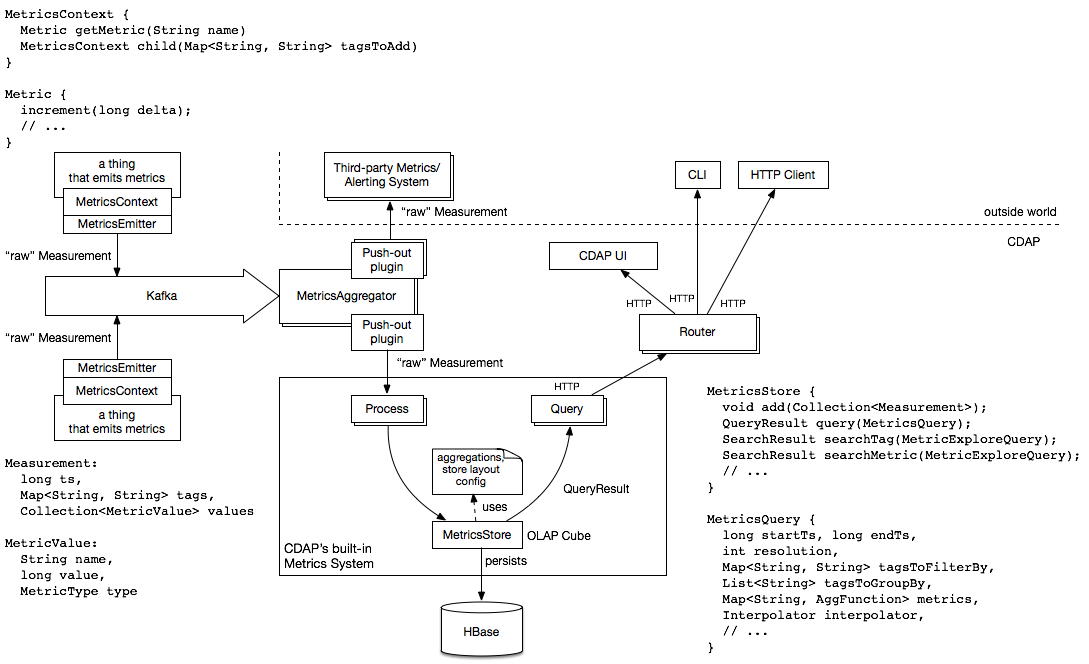
Some details could be found in this blog post: http://blog.cask.co/2015/04/metrics-system-for-data-application-platform/. Also here:
Metrics performance evaluation ( ) gives another high-level view on the current metrics system:

Metrics Collection
Metrics collection is a home grown code. It could be inefficient and create larger overhead, as mentioned above in notes on performance.
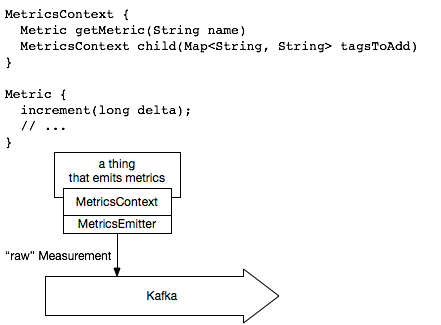
Instead, we should use well-established tools to collect metrics, like Yammer metics or smth like that. The key difference, or uniqueness of CDAP metrics collection is a hierarchical context. But still we can use third party API and wrap into a hierarchical context.
Metrics Processing
Metrics data is processed by MetricsProcessor (CDAP's system service) instances running on YARN.
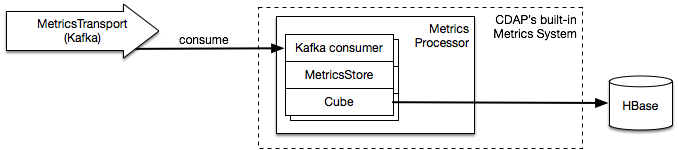
In distributed env data is ultimately stored in HBase using Cube:
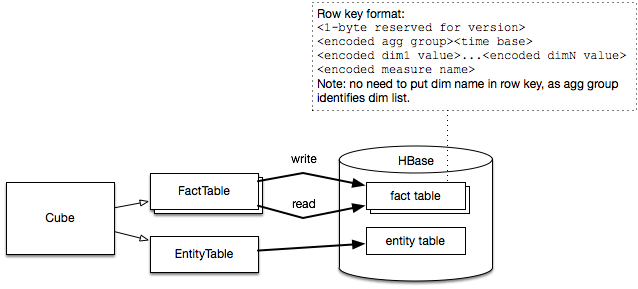
Cube code is also used by Cube dataset. Right now only part of the code is re-used between metrics system and Cube dataset, but we should in future refactor that. Current MetricStore class hierarchy:
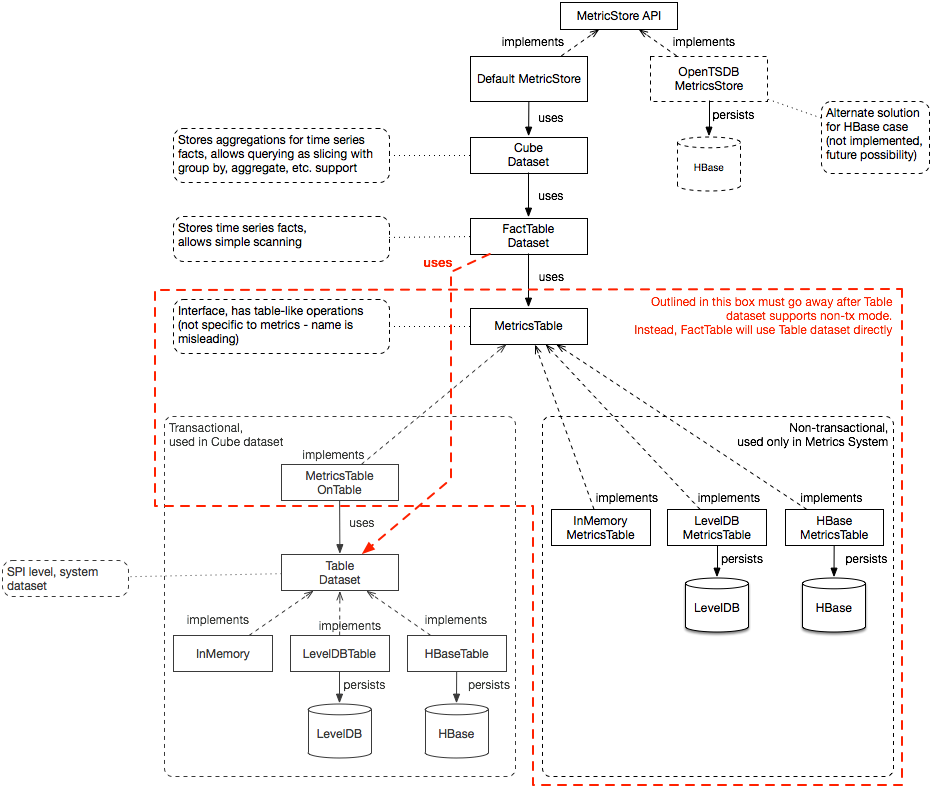
I.e. desired state:
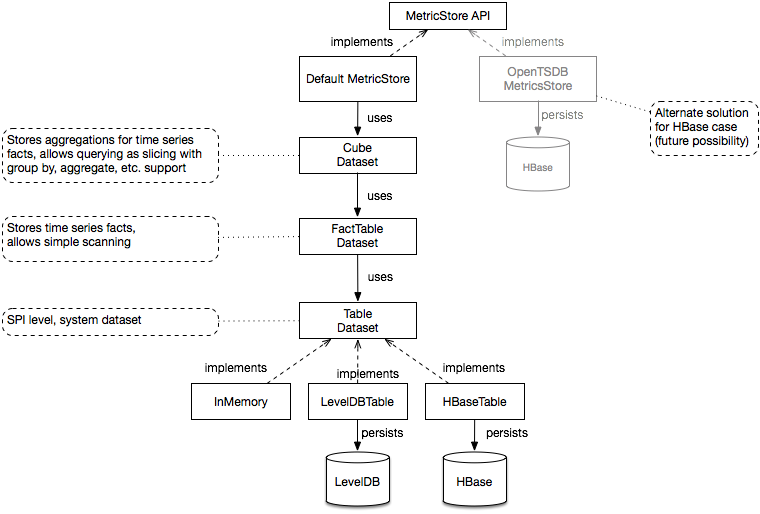
Note that MetricStore provides way to store metrics data and also provides querying capabilities.
As of now, there's only MetricStore implementation that talks directly to underlying storage. There should also be one that talks to MetricsService remotely to be used in non-metrics components/services to allow applying security and other logic in centralized manner.
Metrics Querying
Metrics querying is provided by separate MetricsQueryService (CDAP system service) that can be scaled separately from MetricsProcessor. On the other hand, they are completely independent which makes all data to have to go thru the storage (HBase) and makes it hard to optimize for from-memory queries. It also imposes a complexity of managing separate services and taking up more YARN resources (running separate containers).
Created in 2020 by Google Inc.